[[research/tsifter/TSifter]]の実験でマイクロサービスの実験環境でデータがとれるようになってきた。
- スクリプト:[https://github.com/yuuki/microservices-demo/blob/master/scripts/get_metrics_from_prom.py](https://github.com/yuuki/microservices-demo/blob/master/scripts/get_metrics_from_prom.py#L86-L101)
- [[get_metrics_from_prom.py]]
- JSON: [https://github.com/yuuki/microservices-demo/blob/master/scripts/data/20200807_user-db_cpu-load_02.json](https://github.com/yuuki/microservices-demo/blob/master/scripts/data/20200807_user-db_cpu-load_02.json)
事前知識と利用するために、sock-shop [[Sock Shop]] のPod間のネットワーク通信関係をdot言語で書いた。[https://github.com/yuuki/microservices-demo/blob/master/dot/sockshop.dot](https://github.com/yuuki/microservices-demo/blob/master/dot/sockshop.dot)
Graphvizで可視化できるのだけれど、定義していないエッジが生えたり、定義しているはずのエッジがなかったりと案外難しい。
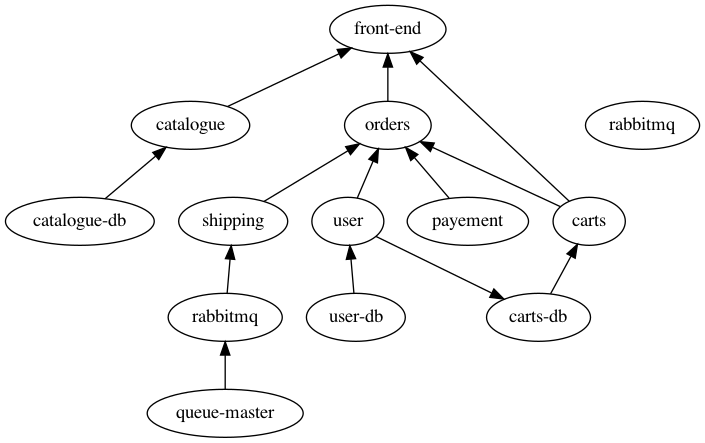
rabbitmqが孤立してておかしい。user → carts-dbのエッジは本来ない。
kubeletから取得可能なcAdvisorメトリックは56個ほどあるが、その中で最低限必用なコンテナメトリックを5個選んだ。
- container_cpu_usage_seconds_total (CPU利用率)
- container_fs_io_current (IOPS)
- container_memory_working_set_bytes (メモリ使用量)
- container_network_receive_bytes_total (ネットワーク受信量)
- container_network_transmit_bytes_total (ネットワーク送信量)
しかし、ネットワーク系のメトリックはPod単位でとれてなくて仕様なのか調査中。
user-dbに対してstress-ngコマンドでCPU負荷を注入したときのグラフが次のダッシュボード。
[https://snapshot.raintank.io/dashboard/snapshot/60c26i6F7glYkBSIOSeQTR3IxEIFmG4N](https://snapshot.raintank.io/dashboard/snapshot/60c26i6F7glYkBSIOSeQTR3IxEIFmG4N)
[https://snapshot.raintank.io/dashboard/snapshot/5lpfuWzF0nLw4F118O4VxvVhlKF3unMu](https://snapshot.raintank.io/dashboard/snapshot/5lpfuWzF0nLw4F118O4VxvVhlKF3unMu)
同一クラスタに対していったん異常を注入すると、時系列データが乱れるので、異常を間を置かずに連続して注入すると、立て続けに障害が起きたデータになってしまう。連続してデータをとりたい場合は、クラスタを複数用意したほうがいいかもしれない。この手の実験はどうしても時間がかかってしまうなあ。