## Overview
### 深層学習による問題解決能力を支える計算基盤
深層学習をはじめとする[Preferred Networks](https://preferred.jp/ja/)(PFN)の中核技術は膨大な計算を要求します。
PFNでは、多量の計算を効率的に実行するために独自の計算機クラスターを複数運用しています。 これらの計算機クラスターはシリーズ毎にナンバリングされており、現在はMN-2、MN-3が稼働しています。
### PFNにおける計算基盤の研究開発
PFNのビジネスや研究開発は膨大な計算能力に支えられており、常に多くの計算需要が存在しています。性能や効率が良い計算基盤を実現するための研究開発はPFNにとって欠かすことができないものです。
GPUやMN-Coreなどの演算アクセラレータを搭載したサーバー群とネットワークやストレージなどの周辺要素を組み合わせてPFNが必要とするワークロードに最適化されたシステム設計をおこない、常に最先端の計算基盤が社内外の研究者や開発者に提供できるようになっています。
独自ASICであるMN-Coreシリーズの開発、MN-Coreシリーズを使いこなすノード構成技術、機械学習などに最適化されたネットワークやインターコネクト技術、収容効率や電力効率の高い物理構成技術など、PFNでは高性能な計算機を実現するために多くの研究開発に取り組んでいます。
## Infrastructure
### MN-3

MN-3は、PFNと神戸大学が共同開発した超低消費電力の深層学習用プロセッサー[MN-Core™](https://projects.preferred.jp/mn-core/)を採用してPFNが2020年5月に構築した第3世代のクラスタです。 PFNではMN-3を用いて[実用的な深層学習のワークロードの高速化](https://www.preferred.jp/ja/news/pr20210614/)を進めています。MN-3は、スーパーコンピュータの省電力性能ランキングGreen500で[2020年6月](https://www.preferred.jp/ja/news/pr20200623/)、[2021年6月](https://www.preferred.jp/ja/news/pr20210628/)、[2022年11月](https://www.preferred.jp/ja/news/pr20211116/)に世界1位となり、世界で最も電力効率エネルギー性能に優れたスーパーコンピュータとして認定されました。
計測に使用したシステム構成および演算性能:
<table><tbody><tr><td></td><td>2022年5月</td><td>2021年11月</td><td>2021年6月</td><td>2020年11月</td><td>2020年6月</td></tr><tr><td>ノード数</td><td colspan="4">32ノード</td><td>40ノード</td></tr><tr><td>MN-Core数</td><td colspan="4">128</td><td>160</td></tr><tr><td>CPU (Intel Xeon)コア数</td><td colspan="4">1,536</td><td>1,920</td></tr><tr><td>ピーク性能(各回の測定条件における理論値)</td><td>3.348 PFlops</td><td>3.390 PFlops</td><td colspan="2">3.138 PFlops</td><td>3.92 PFlops</td></tr><tr><td>連立一次方程式を解く計算速度(HPLベンチマーク)</td><td>2.180 PFlops</td><td>2.181 PFlops</td><td>1.822 PFlops</td><td>1.653 PFlops</td><td>1.621 PFlops</td></tr><tr><td>省電力性能(消費電力1Wあたりの性能)</td><td>40.90 GFlops/W</td><td>39.38 GFlops/W</td><td>29.70 GFlops/W</td><td>26.04 GFlops/W</td><td>21.11 GFlops/W</td></tr><tr><td>Green500リストランキング</td><td>5位</td><td>1位</td><td>1位</td><td>2位</td><td>1位</td></tr></tbody></table>

2021年11月のGreen500 Certificate
Blog記事: [MN-3の高精度電力計測にむけた取り組み](https://tech.preferred.jp/ja/blog/mn-3_green500_202011/)
[TOP500とGreen500:コンピュータの性能指標をどう読むか](https://tech.preferred.jp/ja/blog/top500_green500/)
PFNは、MN-Coreを用いる計算機クラスターの段階的な拡充を計画しており、2020年5月に以下の構成で第一期の構築(MN-3a)が完了しています。

MN-3では、32台のMN-Core Server(計算ノード)を2台のMN-Core DirectConnect Switch で密結合した単位をひとかたまりのZoneと呼びます。
MN-3aは、1.5Zone分の計算ノードで構成されます。
Blog記事: [MN-3が動き出します](https://tech.preferred.jp/ja/blog/mn-3-launch/)

MN-3aクラスターの構成は以下のとおりです。
- MN-Core Server(計算ノード) x 48台
- MN-Core Server間の通信ネットワーク
- MN-Core DirectConnect (MN-Core用に専用開発したインターコネクト技術)
- 100GbE Ethernet
MN-3aの計算ノード1台あたりの構成は以下のとおりです。

(表) MN-Core Server
| MN-Core | MN-Core Board x 4 |
| --- | --- |
| CPU | 2-way (Intel Xeon 8260M) |
| Memory | DDR4 384GB |
| Storage Class Memory | 3TB Intel Optane DC Persistent Memory |
| Network | MN-Core DirectConnect + 100Gbps Ethernet |

Blog記事: [MN-3が動き出します](https://tech.preferred.jp/ja/blog/mn-3-launch/)
## MN-2A

 
MN-2AはGPUを用いた、PFN初の自社構築・管理の計算機クラスターです。2019年7月から運用を開始しています。
MN-2Aクラスターの構成は以下のとおりです。
- GPUサーバー(計算ノード) x 128台
- CPUサーバー(計算ノード) x 32台
- ストレージサーバー x 24台
- Ethernet Switch(100GbE) x 18台
MN-2Aの計算ノード1台あたりの構成は以下のとおりです。

(表) GPUサーバー
| GPU | NVIDIA V100 SXM x 8 |
| --- | --- |
| CPU | Intel Xeon 6254 (2 way/36コア) |
| Memory | DDR4 384GB |
| Network | 400Gbps (100GbE x 4) |
(表) CPUサーバー
| CPU | Intel Xeon 6254 (2 way/36コア) |
| --- | --- |
| Memory | DDR4 384GB |
| Network | 200Gbps (100GbE x 2) |
Blog記事: [MN-2が動き出しました](https://tech.preferred.jp/ja/blog/mn-2-is-up/)
## MN-2B
 
MN-2BはGPUを用いた計算機クラスターです。MN-2Aを拡張する形で構築されており、2022年7月から運用を開始しました。
技術的な特徴はMN-2Aに準拠していますが、最新世代のGPUおよびCPUと大きめの主記憶を搭載しており、より高い計算能力を発揮できるようになっています。PFNの計算ワークロードの分布に合わせて複数種類のGPUを組み合わせたハイブリッドクラスタとなっているのMN-2Bの特徴です。
MN-2Bクラスターの構成は以下のとおりです。
- GPUサーバー(NVIDIA A100) x 42台
- GPUサーバー(NVIDIA A30) x 42台
トータルのGPU数は420個になります。
MN-2Bの計算ノード1台あたりの構成は以下のとおりです。

(表) GPUサーバー (NVIDIA A100)
| GPU | NVIDIA A100(80GB) SXM x 4 |
| --- | --- |
| CPU | AMD EPYC 7713 (2 way/128コア) |
| Memory | DDR4 1024GB |
| Network | 200Gbps (100GbE x 2) |
(表) GPUサーバー (NVIDIA A30)
| GPU | NVIDIA A30(24GB) PCIe x 6 |
| --- | --- |
| CPU | Intel Xeon 8380 (2 way/80コア) |
| Memory | DDR4 512GB |
| Network | 200Gbps (100GbE x 2) |
## 運用が終了したクラスター
MN-1, MN-1b

MN-1およびMN-1bはNTT Communicationsによって構築されたPFN専用のGPU計算機クラスターで、2017年9月(MN-1)および2018年7月(MN-1b)から2022年7月まで約5年間運用されていました。
それぞれのクラスターの構成は以下のとおりです。
- MN-1
- GPUサーバー(NVIDIA P100 x 8, InfiniBand FDR(56Gbps)× 2) x 128台
- MN-1b
- GPUサーバー(NVIDIA V100 x 8, InfiniBand EDR(100Gbps)× 2) x 64台
MN-1を使った取り組み:
- [Preferred Networks、深層学習の学習速度において世界最速を実現](https://preferred.jp/ja/news/pr20171110/)
- [Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes](https://preferred.jp/wp-content/uploads/2017/11/imagenet_in_15min.pdf)
- [Preferred Networksのプライベート・スーパーコンピュータが Top 500リストのIndustry領域で国内1位に認定](https://preferred.jp/ja/news/pr20171114/)
MN-1bを使った取り組み:
- [世界454チームが参加した物体検出コンペティション Google AI Open Images - Object Detection Trackで準優勝](https://preferred.jp/ja/news/pr20180907/)
- [PFDet: 2nd Place Solution to Open Images Challenge 2018 Object Detection Track](https://arxiv.org/abs/1809.00778)
## Computing Sites
- JAMSTEC (国立研究開発法人 海洋研究開発機構) 横浜研究所 シミュレータ棟内
- MN-2, MN-3
- 施設の一部を借用し、独立運用
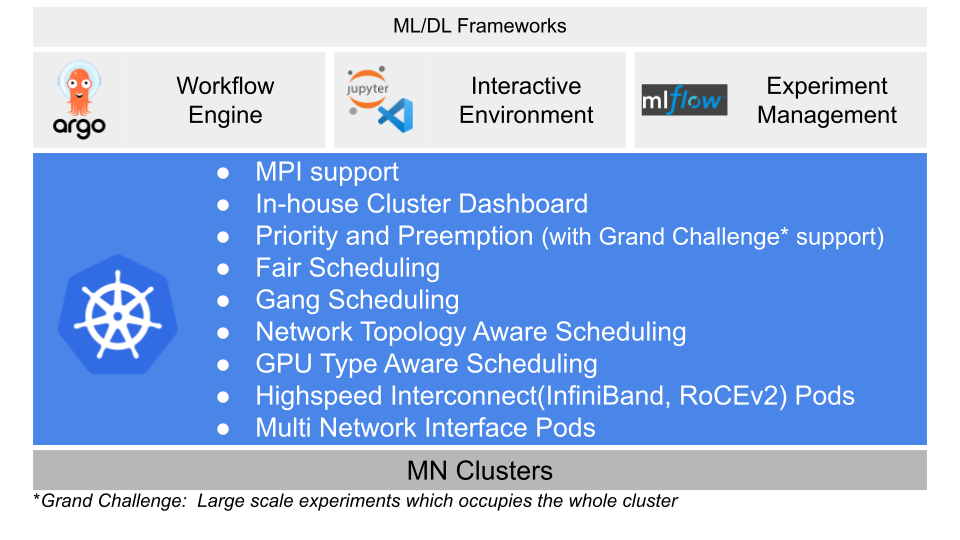
## Middleware
PFNの計算機クラスターでは、OSSである[Kubernetes](https://kubernetes.io/)をコア技術として採用し、独自に開発したスケジューラやフロントエンドを用いることで、機械学習・深層学習を効率よく実行するためのプラットフォームを構築しています。