本記事は、[2024年夏季インターンシッププログラム](https://www.preferred.jp/ja/news/internship2024/)で勤務された岡部 純弥さんによる寄稿です。
---
## はじめに
こんにちは。筑波大学大学院修士1年の岡部 純弥です。インターンシップでは、「PFCP向けログ基盤の構築」というテーマで、PFCPにおけるログ基盤の設計・構築・検証を行いました。
## PFCPについて
### PFCPとは
PFCP (Preferred Computing Platform) はPFNが構築・運用するクラウドサービスです。PFNが開発する独自アクセラレータであるMN-Core™を利用でき、AIワークロードに適しています。参考:
- [AIプロセッサーMN-Core 2を計算資源とした AI向けクラウドサービスPreferred Computing Platformを提供開始 – 株式会社Preferred Networks](https://www.preferred.jp/ja/news/pr20241021/)
- [PFN、深層学習を高速化するプロセッサーMN-Core 2の開発および、MN-Coreシリーズのクラウドサービス構想を発表](https://www.preferred.jp/ja/news/pr20221214/)
PFCPのユーザーは、Kubernetes上で動作するワークロードとして大規模分散学習や推論サーバーを運用することができます。
### PFCPのアーキテクチャ
以下にPFCPのアーキテクチャを示します。DC (Data Center) は実際にPFNが所有しているベアメタルが置かれているデータセンターを指しています。DC内のノードの多くはMN-Coreを搭載した計算ノードです。
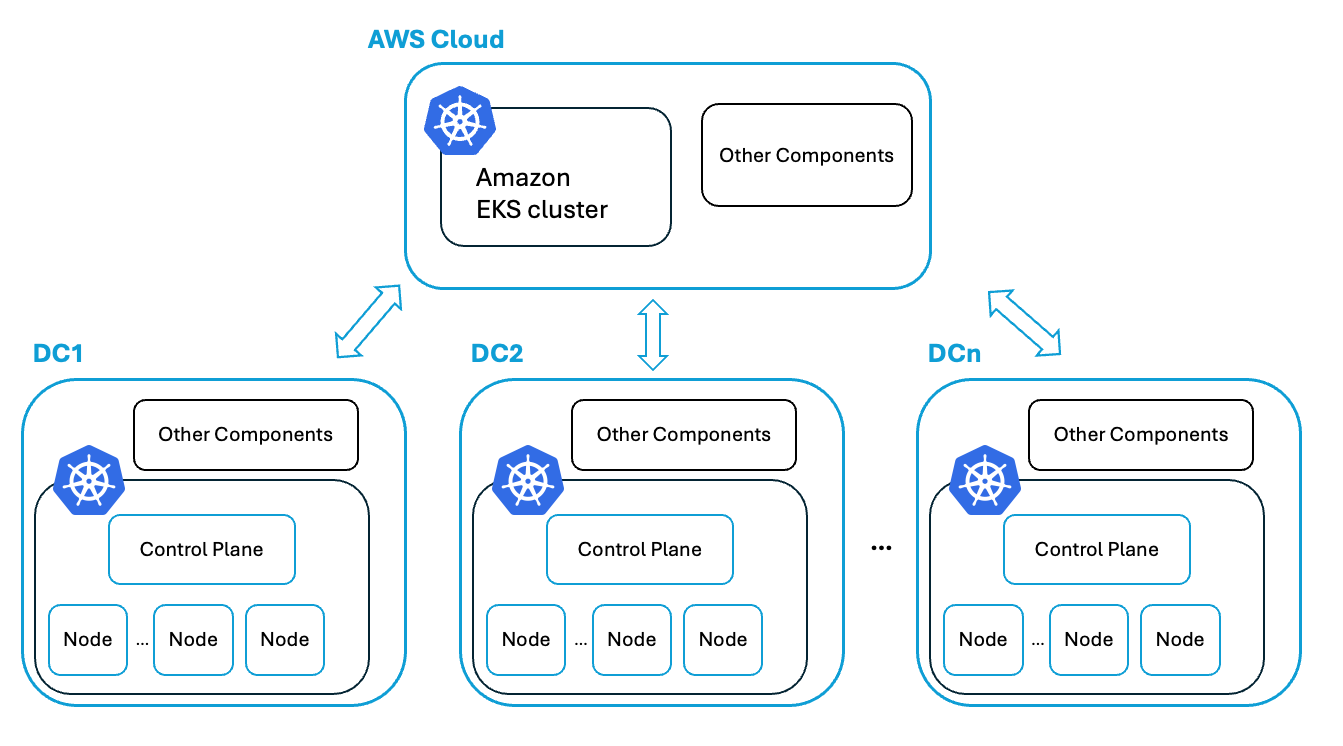
PFCPのアーキテクチャ
PFCPは、主に各DC内のKubernetesクラスター、およびそれらを管理するためのAWS上のEKSクラスターによって構成されています。各DC内のクラスターは、多くの計算ノードをもつKubernetesクラスターであり、コントロールプレーンも含めてオンプレミスで稼働しています。EKS上では各DCのKubernetesクラスターを管理するためのコンポーネントなどが動いており、各DCと相互に接続されています。
また、PFCPはマルチテナントであり、複数のテナントのユーザーが同一のKubernetesクラスターを使用します。マルチテナントKubernetesにおけるセキリュティ確保のための取り組みは、以下で紹介されています。
- [マルチテナントマルチクラスタKubernetesでもUXを損なわない認証認可の勘所](https://speakerdeck.com/pfn/20240517_cncj_kickoff_pfn)
### PFCPでのログ基盤
システム監視の三大項目の一つに、ログがあります。Podやデーモン、システムからのログは永続化されないものの、デバッグや二次分析等の用途で必要になります。そのため、ログの集約・可視化をおこなうログ基盤の構築が重要です。
また、PFCPでは、計算機リソースの提供だけではなく、ユーザー向けにいくつかのマネージドサービスを提供します。その中の一つとして、ログを含めワークロードの状況を観測するためのマネージドモニタリングサービスがあります。このサービスを利用することで、ユーザーはユーザー自身が実行したいワークロードの構築や運用に集中することができます。このサービスの実現のためにも、ログ基盤の構築が必要です。
今回のインターンシップでは、このログ基盤の構築、特にクラスター管理者向けのシステムログ基盤構築のための技術検証を中心に取り組みました。
## 技術選定
### ログ処理ツールの技術選定
Kubernetes上にログの処理を行うツールを導入する場合、Grafana LokiやElasticsearchのようなソフトウェアが挙げられます。今回は主に以下の理由でGrafana Lokiを採用することにしました。
- PFCPではすでにGrafanaやPrometheusが導入されており、Lokiはこれらとの連携が容易
- マルチテナントを前提とした設計になっており、これはPFCPでの要件に合致している
### Grafana Lokiとは
[Grafana Loki](https://grafana.com/oss/loki/)について簡単に説明します。Lokiは監視の三大項目であるメトリクス・ログ・トレースのうちログを担当するコンポーネントです。[https://github.com/grafana/loki](https://github.com/grafana/loki) に “Like Prometheus, but for logs” と記載されているように、Prometheusに影響を受けています。しかし、PrometheusがPull型のアーキテクチャであるのに対して、LokiはPush型のアーキテクチャを採用しています。つまりログの収集を行うエージェントが、Lokiに対してログを送信します。
Lokiのアーキテクチャを以下に記載します。
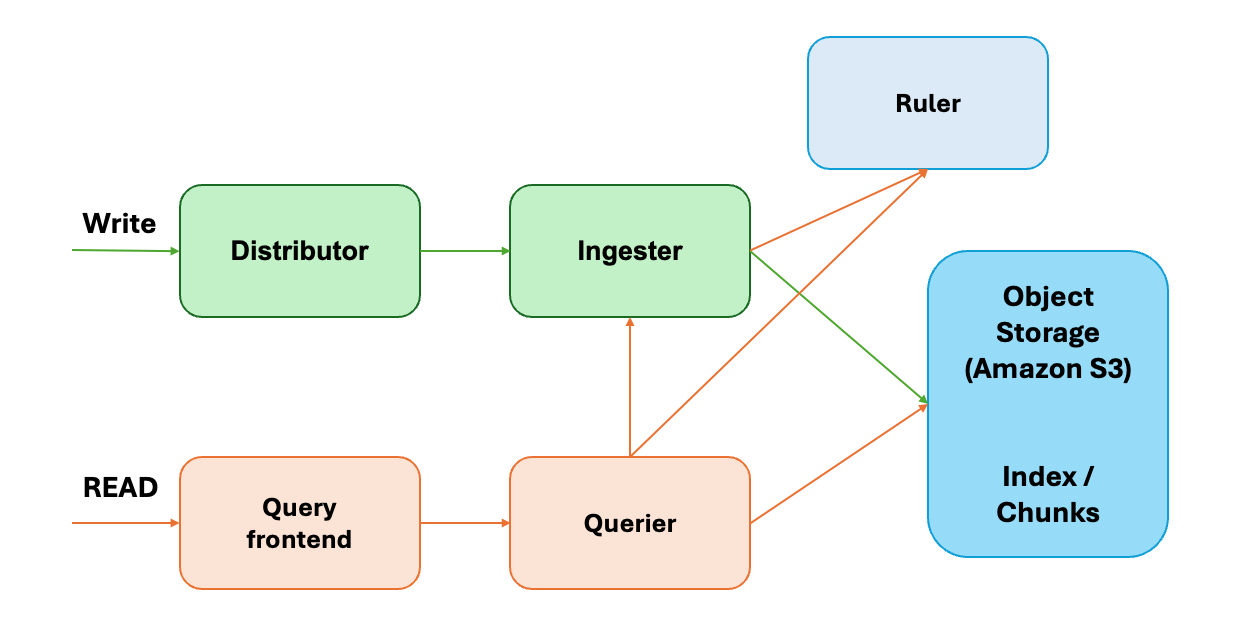
Lokiのアーキテクチャ
Lokiはいくつものコンポーネントがモジュラーに動作するアーキテクチャになっています。それゆえ、各コンポーネントは独立にスケールします。
各コンポーネントについて簡単に記載します。
- Distributor: ログを追記するリクエストのハンドル
- 複数台のIngestorにログをフォワードする
- Ingester: 一定期間ログをメモリバッファに記憶し、Object Storageにフラッシュする
- Query frontend / Querier: 検索クエリを発行する
- Ruler: AlertManagerにアラートを飛ばす
- Object Storage: Index / Chunksの保存先
### ログ収集エージェントの技術選定
ログ処理ツール同様、各ノードやコントロールプレーンのログを収集し、Lokiにログを送信するエージェントにも選択の余地があります。Lokiがサポートしているログ収集エージェントの候補としては、以下のようなソフトウェアが挙げられます。
- Promtail
- Grafana Alloy (Grafana Agentの後継)
- Fluentd / Fluent Bit
- Logstash
今回は主に以下の理由で[Grafana Alloy](https://grafana.com/docs/alloy/latest/)を採用しました。
- OpenTelemetry Collectorと完全な互換性があり、ベンダーロックインされる可能性が低い
- ログだけではなく、メトリクスやトレースもサポートされている
- Grafana Agentの精神的な後継であり、LokiやGrafanaとの互換性・安定性に優れている(ことが期待できる)
## ログシステムの構築
### アーキテクチャ
構築するログ基盤のアーキテクチャを以下に示します。赤線で囲まれているコンポーネントが今回のインターンシップで新たに検証・構築した箇所です。検証の際は、実際のDCではなく手元のマシンにk8sクラスターを立てて、そこからログの送信を行いました
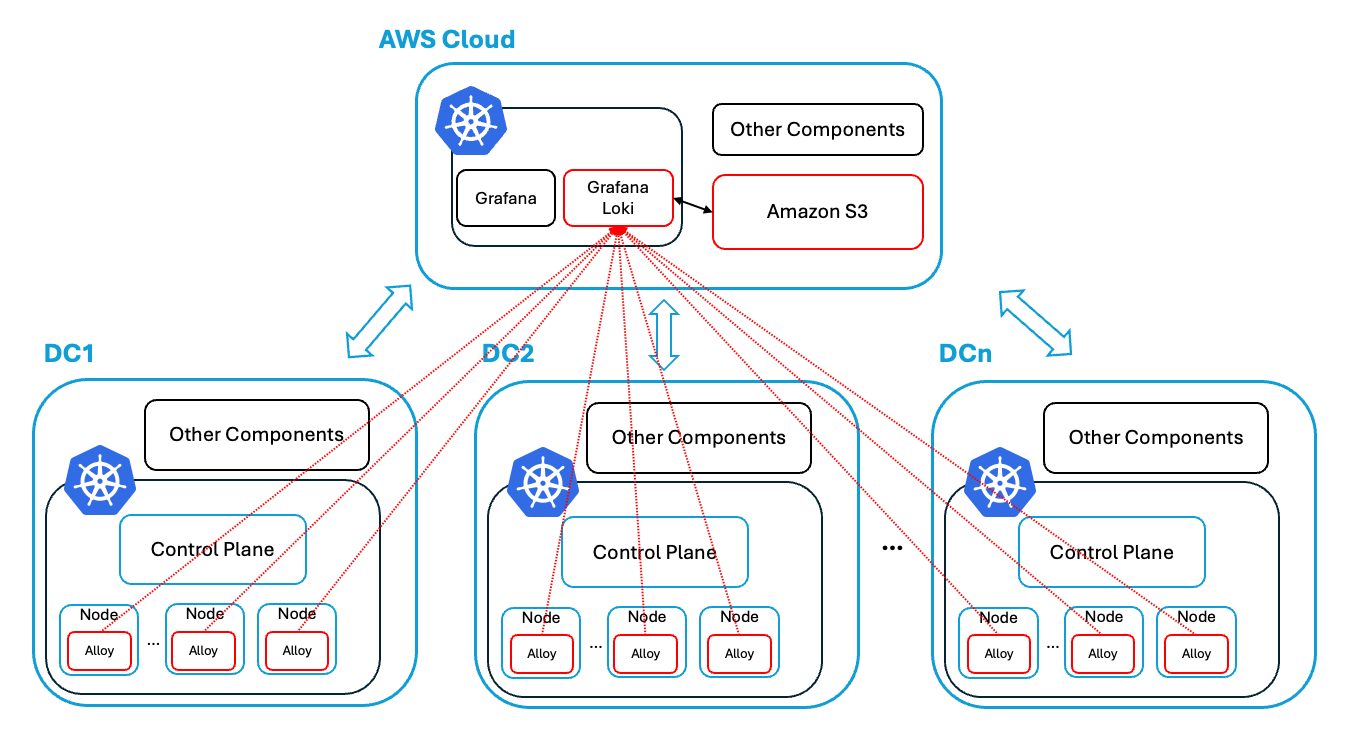
ログ基盤のアーキテクチャ
今回はLokiをEKS上にのみ構築し、各DCのエージェントからログを送信するアーキテクチャを採用しました。各DCごとにLokiを構築し、Grafanaが各Lokiインスタンスにクエリを発行するアーキテクチャも検討の余地があります。しかし、各DCにLokiを構築すると、Grafanaからクエリを発行するたびにAWS – DC間で通信が発生します。これを防ぐため、EKS上にLokiを構築しました。
もちろん採用したアーキテクチャでは全てのログがDCからAWSに送信されるため、この間の通信量が大きくなります。各DCで収集するログを適切に絞ることで、この影響を抑えられると考えています。
### ログシステムの構築
上述したアーキテクチャに沿って、ログシステムの構築を行います。
まず各DCのすべてのノード上にログ収集エージェントであるGrafana AlloyをPodとしてデプロイします。これはGrafana AlloyをDaemonSetとしてデプロイすることで容易に実現できます。Helm Chartsを用いてGrafana Alloyをデプロイすると、[デフォルトでDaemonSetとしてデプロイされます](https://github.com/grafana/alloy/blob/f9054d30ed46ade7a2f87af688e5860410c3ac31/operations/helm/charts/alloy/values.yaml#L165)。
またEKSクラスター上にGrafana Lokiを構築します。Grafana LokiもHelm Chartsが公開されているため、これを用いて構築することができます。Lokiを構築する際は、いくつか注意する点があります。
- Lokiはデプロイ時にMonolithic mode、Simple Scalable、Microservices modeのどのモードでデプロイするか選択する必要があります。詳しい説明は[Loki deployment modes](https://grafana.com/docs/loki/latest/get-started/deployment-modes/)に譲りますが、モードによって設定可能なHelm Valuesが若干異なります
- 先述した通り、Lokiはマルチテナントを前提とした設計になっています。テナントの識別はHTTPリクエストの`X-Scope-OrgID`ヘッダーによって行われるため、このヘッダーが付与されていないリクエストはクライアントエラーになります。検証等の理由で、シングルテナントで使用したい場合は、`auth_enabled`フィールドを`false`に設定する必要があります
- デプロイモードによりますが、Lokiはデフォルトで数Gi〜数十Gi程度のメモリリソースを要求します。検証等で使用する場合、メモリ使用量を抑えるためのパッチをあてる、あるいは一時的に十分なメモリを持っているノードの使用を検討する必要があります
これらに注意した上で、以下のような `values.yaml` を書くことでLokiをKubernetesクラスターにデプロイすることができます。なお、これは実際の動作を保証するものではありません。デプロイ先の環境に応じて、適宜書き換えてください。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | `loki:` `auth_enabled: false` `commonConfig:` `replication_factor: 1` `storage:` `type: s3` `bucketNames:` `chunks: "loki-chunks"` `ruler: "loki-ruler"` `admin: "loki-admin"` `s3:` `endpoint: "${s3Endpoint}"` `region: ap-northeast-1` `accessKeyId: "${accessKeyId}"` `secretAccessKey: "${secretAccessKey}"` `s3ForcePathStyle: true` `insecure: true` `http_config:` `insecure_skip_verify: true` `schemaConfig:` `configs:` `- from: "2024-01-01"` `store: tsdb` `index:` `prefix: loki_index_` `period: 24h` `object_store: s3` `schema: v13` `deploymentMode: SimpleScalable` `backend:` `replicas: 3` `read:` `replicas: 3` `write:` `replicas: 3` |
| --- | --- |
これらの構築を行い、Loki (frontend)に対してクエリを発行することで、集約されたログを確認することができます(Grafanaを経由してログを確認する方が簡単だと思います)。
Grafana上でのログの確認
## 感想・謝辞
監視やロギングに対する知識や経験が豊富ではなく、大変なことも多かったですが、メンターの薮内さん、秋田さんをはじめとした受け入れ先チームの皆様、他のインターン生の多大なサポートによって検証を進めることができました。この場を借りて改めて御礼を申し上げます。
チームの方々や他のインターン生と交流する機会も多く、計算機やソフトウェアに関するお話がたくさんできてとても楽しいインターンとなりました!