[東大松尾・岩澤研究室 | LLM開発 プロジェクト\[GENIAC\]](https://zenn.dev/p/matsuolab) [Publicationへの投稿](https://zenn.dev/faq#what-is-publication)
13[tech](https://zenn.dev/tech-or-idea)
## はじめに
この記事の内容は、以下の勉強会で報告したものになります。
**開催日時** :2024年10月27日(日)17:00 - 19:00
**テーマ** : [**小型LlamaモデルのMegatron-LMを用いた事前学習と継続事前学習**](https://matsuolab-community.connpass.com/event/334130/)
この勉強会では、 **Megatron-LMの説明** に加えて、トークナイザーや事前学習や継続事前学習についても報告を行っています。本記事と合わせてご活用ください。
## 1\. Megatron-LMの説明
Megatron-LMは、NVIDIAが開発した大規模言語モデル(LLM)のトレーニングフレームワークです。GPT、BERT、T5などの様々な種類の言語モデルを効率的にトレーニングできるように設計されています。
Megatron-DeepSpeedはMicrosoftが開発したDeepSpeedによる学習・推論効率化技術を、Megatron-LM に追加することで出来た、Transformerモデルの学習・推論フレームワークです。
Phase-1ではチームtanukiはMegatron-DeepSpeedを使用いたしましたが、Megatron-LMのみでTransformer-engineに対応していること、Tanuki-8x8Bのような大規模なMoEの学習をサポートしていることから、phase-2ではMegatron-LMを採用いたしました。
GENIAC松尾研プロジェクトTanukiチームでは、requirement等が整備されており、condaでの環境構築の再現が可能なllm-jpにて公開していただいているレポジトリを使用させていただきました。
| 年 | フレームワーク | 開発元 | 簡単な説明 | GitHub URL |
| --- | --- | --- | --- | --- |
| 2019 | Megatron-LM | NVIDIA | Transformerモデルの学習を効率化するフレームワーク。Tensor ParallelismやPipeline Parallelismを活用して分散トレーニングを実現。 | [GitHub](https://github.com/NVIDIA/Megatron-LM) |
| 2020 | DeepSpeed | Microsoft | ZeRO Optimizer(バージョン0, 1, 2, 3)によりメモリ効率を大幅に向上し、超大規模モデルのトレーニングを可能にする。 | [GitHub](https://github.com/microsoft/DeepSpeed) |
| 2021 | Megatron-DeepSpeed | Microsoft | NVIDIAのMegatron-LMとMicrosoftのDeepSpeedを統合し、大規模モデルのスケーリングと効率的なトレーニングを両立。 | [GitHub](https://github.com/microsoft/Megatron-DeepSpeed) |
| 2024 | Megatron-DeepSpeed LM(llmjp版) | NVIDIA (llmjp) | 日本のllmjpが使用するMegatron-LMバージョン。wandbの各種ログの追加やdatasetの読み込みの効率化、特定のタスク向けの最適化が行われている。 | [GitHub](https://github.com/llm-jp/Megatron-LM) |
## 2\. 分散学習設定
Megatron-LMはMegatron-LMでは、分散学習設定として3D Parallelismを適用しています。3D ParallelismとはData Parallel(学習データの分割) + Tensor Parallel(モデルの分割) + Pipeline Parallel(モデルのtransformerブロック方向の分割)のことを指します。以下に概要図を示します。(引用元: [DeepSpeed: Extreme-scale model training for everyone - Microsoft Research](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/))
この技術を採用することにより、GPUの容量以上のモデルを用いても学習が可能となります。tanukiでは以下の設定を用いて学習を行いました。Geniacの環境では、Pipeline Parallelを採用する方が速度が出たことにより、本分割にて学習を実施しました。また、学習速度に関しては使用するnode数によって異なりました。
| モデル名 | TP | PP |
| --- | --- | --- |
| tanuki-8B | 1 | 4 |
| tanuki-8x8B | 1 | 16 |
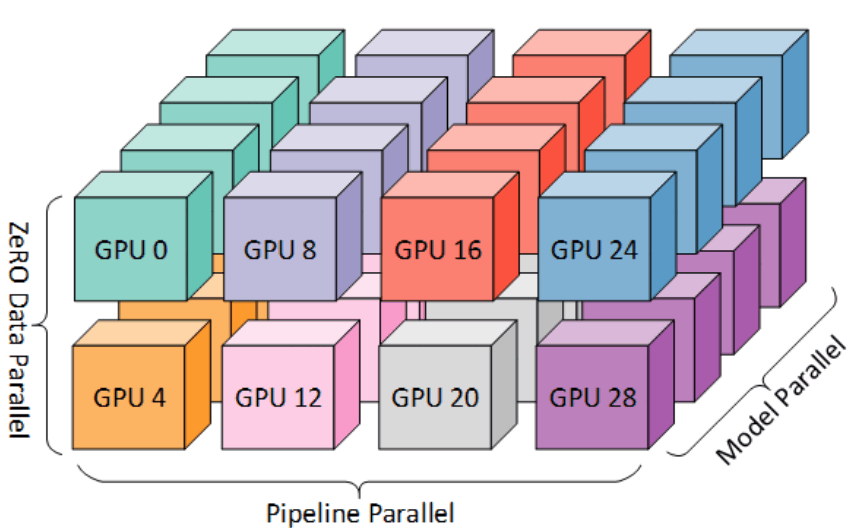
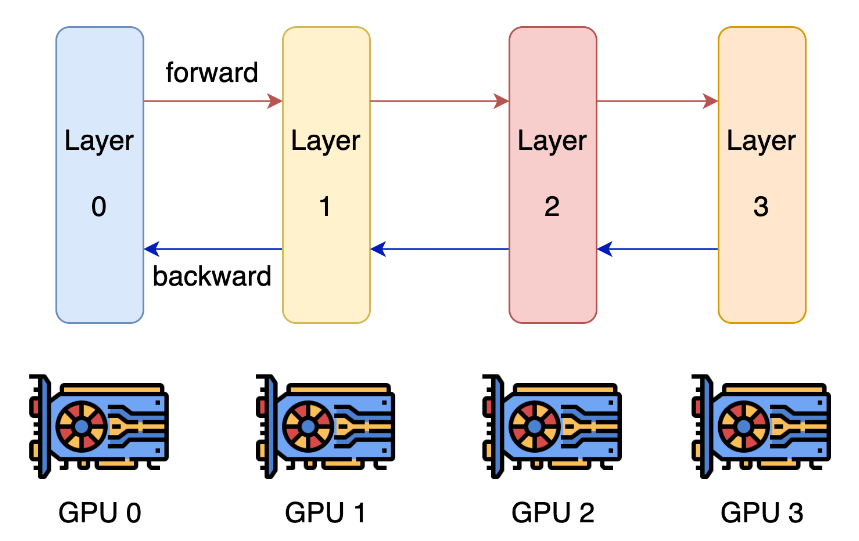
[pipeline parallismの概要図](https://colossalai.org/docs/concepts/paradigms_of_parallelism/#pipeline-parallel)
また、各種3D Parallelismの設定に対する学習速度の比較例を示します。
| Micro batch | TP | PP | TFlops |
| --- | --- | --- | --- |
| 1 | 2 | 4 | 89 |
| 1 | 1 | 8 | 185 |
| 2 | 1 | 16 | 246 |
| 4 | 2 | 8 | 240 |
| 6 | 2 | 8 | Out of Memory |
## 3\. Distributed OptimizerとDeep Speedについて
Megatron-DeepSpeedはMegatron-LMのフレームワークに以下のDeepSpeedの技術を適用しています。以下に代表的な技術について記載します。
- ZeRO(Zero Redundancy Optimizer):モデルの状態を分散して保存し、メモリ使用量を削減
ZeRO 1ではoptimezerをZeRO2ではoptimizerに加えてgadientを、ZeRO3では更にモデルのパラメータを分散共有しています。(図は [ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters - Microsoft Research](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/?msockid=1152f278eec160492d1ae693ef4a617c) より)
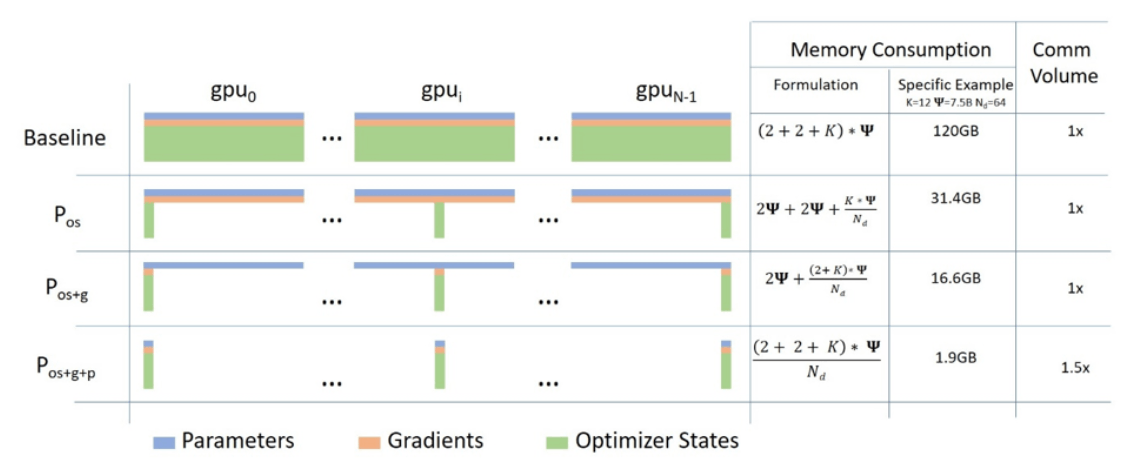
- オフロード技術:CPU、NVMeなどにデータを一時的に移動させてGPUメモリを節約
phase-1ではZeRO 1を採用することで、スピードの低下を最低限にしながら、GPUメモリを最適化して学習を実施しました。
Megatron-LMではDistributed Optimizerを利用することでDeepSpeed ZeRO 1のようにOptimizer Statesを分散して保有することで、メモリの効率的な利用を実現しました。
## 4\. パラメータの設定
```bash
#!/bin/bash
#checkpoint conversion
#/storage5/shared/hatakeyama/0611te/Megatron-LM/scripts/tsubame/ckpt/hf_to_megatron_llama3-8b_0627.sh
source /storage5/shared/jk/miniconda3/etc/profile.d/conda.sh
conda activate share-jk_py310_TEv1.7_FAv2.5.7
export CUDA_DEVICE_MAX_CONNECTIONS=1
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
#**********************
#マスターノードをせっていする
MASTER_ADDR=slurm0-a3-ghpc-6
#**********************
MASTER_PORT=65534
#NODE_RANK=${1}
echo "Node rank: "$NODE_RANK
NODE_RANK=0
NNODES=1
GPUS_PER_NODE=8
echo "MASTER_ADDR=${MASTER_ADDR}"
# hostfile
export NUM_GPU_PER_NODE=8
model_size=8
NUM_LAYERS=32
HIDDEN_SIZE=4096
FFN_HIDDEN_SIZE=14336 # hiddensizeの3.5倍
NUM_HEADS=32
NUM_KEY_VALUE_HEADS=8
SEQ_LENGTH=2048
# distributed settings
TENSOR_PARALLEL_SIZE=1
PIPELINE_PARALLEL_SIZE=2
CONTEXT_PARALLEL_SIZE=1
# training config
MICRO_BATCH_SIZE=1
GLOBAL_BATCH_SIZE=1536
TRAIN_STEPS=12500
LR_DECAY_ITERS=12500
LR=1.0E-4
MIN_LR=1.0E-6
LR_WARMUP_STEPS=1000
WEIGHT_DECAY=0.1
GRAD_CLIP=0.8
# model config
TOKENIZER_MODEL="/storage5/split/split/tokernizer/tokenizer_scale200.model"
CHECKPOINT_DIR="/storage5/shared/Llama-3-8b/tp${TENSOR_PARALLEL_SIZE}-pp${PIPELINE_PARALLEL_SIZE}"
CHECKPOINT_SAVE_DIR="/storage5/shared/Llama-3-8/tp${TENSOR_PARALLEL_SIZE}-pp${PIPELINE_PARALLEL_SIZE}-ct${CONTEXT_PARALLEL_SIZE}-LR${LR}-MINLR${MIN_LR}-WD${WEIGHT_DECAY}-WARMUP${LR_WARMUP_STEPS}"
log_path="${CHECKPOINT_SAVE_DIR}/log"
TRAIN_DATA_PATH="/storage5/split/split/split/tokenized_text_document"
mkdir -p ${CHECKPOINT_SAVE_DIR}
mkdir -p ${log_path}
# checkpoint load
#if [[ -f "${CHECKPOINT_SAVE_DIR}/latest_checkpointed_iteration.txt" ]]; then
# resume training
# CHECKPOINT_ARGS="--load ${CHECKPOINT_SAVE_DIR}"
#else
# first training
# CHECKPOINT_ARGS="--load ${CHECKPOINT_SAVE_DIR} --no-load-rng --no-load-optim"
#fi
#finetune
CHECKPOINT_SAVE_DIR=/storage5/shared/checkpoints/llama8b_test_tp1_pp2
CHECKPOINT_ARGS="--load ${CHECKPOINT_SAVE_DIR} --finetune"
JOB_NAME="Llama-3-8b-0627_hatakeyama_test"
# run
megatron_options=" \
--tensor-model-parallel-size ${TENSOR_PARALLEL_SIZE} \
--pipeline-model-parallel-size ${PIPELINE_PARALLEL_SIZE} \
--context-parallel-size ${CONTEXT_PARALLEL_SIZE} \
--sequence-parallel \
--use-distributed-optimizer \
--num-layers ${NUM_LAYERS} \
--hidden-size ${HIDDEN_SIZE} \
--ffn-hidden-size ${FFN_HIDDEN_SIZE} \
--num-attention-heads ${NUM_HEADS} \
--group-query-attention \
--num-query-groups ${NUM_KEY_VALUE_HEADS} \
--seq-length ${SEQ_LENGTH} \
--max-position-embeddings ${SEQ_LENGTH} \
--micro-batch-size ${MICRO_BATCH_SIZE} \
--global-batch-size ${GLOBAL_BATCH_SIZE} \
--train-iters ${TRAIN_STEPS} \
--tokenizer-type SentencePieceTokenizer \
--tokenizer-model ${TOKENIZER_MODEL} \
${CHECKPOINT_ARGS} \
--save ${CHECKPOINT_SAVE_DIR} \
--data-path ${TRAIN_DATA_PATH} \
--split 998,1,1 \
--distributed-backend nccl \
--init-method-std 0.008 \
--lr ${LR} \
--min-lr ${MIN_LR} \
--lr-decay-style cosine \
--lr-decay-iters ${LR_DECAY_ITERS} \
--weight-decay ${WEIGHT_DECAY} \
--clip-grad ${GRAD_CLIP} \
--lr-warmup-iters ${LR_WARMUP_STEPS} \
--optimizer adam \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--adam-eps 1e-05 \
--log-interval 1 \
--save-interval 500 \
--eval-interval 10000 \
--eval-iters 10 \
--bf16 \
--use-checkpoint-args \
--untie-embeddings-and-output-weights \
--no-position-embedding \
--position-embedding-type rope \
--rope-theta 500000.0 \
--disable-bias-linear \
--use-mcore-models \
--normalization RMSNorm \
--norm-epsilon 1e-5 \
--no-masked-softmax-fusion \
--attention-dropout 0.0 \
--hidden-dropout 0.0 \
--swiglu \
--use-flash-attn \
--attention-softmax-in-fp32 \
--recompute-activations \
--recompute-granularity "selective" \
--transformer-impl "transformer_engine" \
--fp8-format 'hybrid' \
--fp8-amax-compute-algo max \
--fp8-amax-history-len 1024 \
--use-z-loss \
--log-throughput \
--wandb-name ${JOB_NAME} \
--wandb-project "Llama-3-8B" \
--wandb-entity "weblab-geniac1" \
"
current_time=$(date "+%Y.%m.%d_%H.%M.%S")
log_file="${log_path}/llma3_8B_${node_rank}_${current_time}.log"
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
#run_cmd="torchrun $DISTRIBUTED_ARGS $TE_INSTALL_DIR/Megatron-LM/pretrain_gpt.py
#run_cmd="torchrun $DISTRIBUTED_ARGS /storage5/shared/jk/Megatron-LM/pretrain_gpt.py
# ${megatron_options} \
# 2>&1 | tee ${log_file}"
if [[ $node_rank -gt 0 ]]; then
log_file="${log_path}/llma3_8B_${node_rank}_${current_time}.log"
run_cmd="torchrun $DISTRIBUTED_ARGS /storage5/shared/jk/Megatron-LM/pretrain_gpt.py
${megatron_options} \
2>&1 | tee ${log_file}"
else
run_cmd="torchrun $DISTRIBUTED_ARGS /storage5/shared/jk/Megatron-LM/pretrain_gpt.py
${megatron_options}"
fi
echo ${run_cmd}
eval ${run_cmd}
set +x
```
### 4\. megatronの引数について
### 4.1 モデルの構造と並列化
- **`-tensor-model-parallel-size ${TENSOR_PARALLEL_SIZE}`:** テンソル並列化のサイズ
- **`-pipeline-model-parallel-size ${PIPELINE_PARALLEL_SIZE}`:** パイプライン並列化のサイズ
- **`-context-parallel-size ${CONTEXT_PARALLEL_SIZE}`:** コンテキスト並列化のサイズ
- **`-sequence-parallel`:** シーケンス並列化の有無
- **`-num-layers ${NUM_LAYERS}`:** Transformerモデルの層数
- **`-hidden-size ${HIDDEN_SIZE}`:** モデルの隠れ層の次元数
- **`-ffn-hidden-size ${FFN_HIDDEN_SIZE}`:** Feed-Forward Network の隠れ層の次元数
- **`-num-attention-heads ${NUM_HEADS}`:** Attentionheadsの数
- **`-group-query-attention`:** グループ化されたクエリアテンションを有無
- **`-num-query-groups ${NUM_KEY_VALUE_HEADS}`:** クエリグループの数
### 4.2 学習設定
- **`-seq-length ${SEQ_LENGTH}`:** 入力シーケンスの最大長
- **`-max-position-embeddings ${SEQ_LENGTH}`:** 位置エンコーディングの最大長
- **`-micro-batch-size ${MICRO_BATCH_SIZE}`:** マイクロバッチサイズ
- **`-global-batch-size ${GLOBAL_BATCH_SIZE}`:** グローバルバッチサイズ
- **`-train-iters ${TRAIN_STEPS}`:** 学習ステップ数
- **`-tokenizer-type SentencePieceTokenizer`:** トークナイザーとして SentencePiece の有無
- **`-tokenizer-model ${TOKENIZER_MODEL}`:** トークナイザーモデルのパス
- **`-data-path ${TRAIN_DATA_PATH}`:** 学習データのパス
- **`-split 998,1,1`:** データを訓練データ、検証データ、テストデータに分割する割合
- **`-distributed-backend nccl`:** 分散処理に NCCL を使用有無
- **`-init-method-std 0.008`:** 初期化方法の標準偏差
- **`-lr ${LR}`:** 学習率
- **`-min-lr ${MIN_LR}`:** 最小学習率
- **`-lr-decay-style cosine`:** 学習率の減衰方法としてコサイン減衰
- **`-lr-decay-iters ${LR_DECAY_ITERS}`:** 学習率を減衰させる総ステップ数
- **`-weight-decay ${WEIGHT_DECAY}`:** 重み減衰
- **`-clip-grad ${GRAD_CLIP}`:** 勾配クリッピングの閾値
- **`-lr-warmup-iters ${LR_WARMUP_STEPS}`:** 学習率のウォームアップステップ数
- **`-optimizer adam`:** optimizerの設定としてAdam
- **`-adam-beta1 0.9`:** Adam オプティマイザのベータ1パラメータ
- **`-adam-beta2 0.95`:** Adam オプティマイザのベータ2パラメータ
- **`-adam-eps 1e-05`:** Adam オプティマイザのエプシロン値
- **`-log-interval 1`:** ログ出力のインターバル
- **`-save-interval 500`:** チェックポイントを保存するインターバル
- **`-eval-interval 10000`:** 評価を行うインターバル
- **`-eval-iters 10`:** 評価時に使用するバッチ数
### 4.3 モデルの最適化とハードウェア
- **`-bf16`:** BF16
- **`-use-checkpoint-args`:** チェックポイント
- **`-untie-embeddings-and-output-weights`:** エンベディングと出力重み
- **`-no-position-embedding`:** 位置エンコーディング
- **`-position-embedding-type rope`:** 位置エンコーディングとして RoPE (Rotary Position Embeddings)
- **`-rope-theta 500000.0`:** RoPE のパラメータ
- **`-disable-bias-linear`:** 線形層のバイアスの未使用
- **`-use-mcore-models`:** MCore モデル使用
- **`-normalization RMSNorm`:** 正規化として RMSNorm を用
- **`-norm-epsilon 1e-5`:** RMSNorm のイプシロン値
- **`-no-masked-softmax-fusion`:** マスク付きソフトマックスの融合無効
- **`-attention-dropout 0.0`:** アテンション層のドロップアウト率
- **`-hidden-dropout 0.0`:** 隠れ層のドロップアウト率を
- **`-swiglu`:** SwiGLU 活性化関数
- **`-use-flash-attn`:** Flash Attention
- **`-attention-softmax-in-fp32`:** アテンションのソフトマックス計算を FP32
- **`-recompute-activations`:** 活性化関数の再計算を有効
- **`-recompute-granularity "selective"`:** 再計算の粒度を
- **`-transformer-impl "transformer_engine"`:** Transformer エンジンの実装を使用すること
- **`-fp8-format 'hybrid'`:** FP8 フォーマット
- **`-fp8-amax-compute-algo max`:** FP8 の最大値計算アルゴリズム
- **`-fp8-amax-history-len 1024`:** FP8 の最大値計算履歴の長さ
- **`-use-z-loss`:** Z-Loss
- **`-log-throughput`:** スループットのログ出力
### 4.4 実験管理
- **`-wandb-name ${JOB_NAME}`:** Weights & Biases のジョブ名
- **`-wandb-project "Llama-3-8B"`:** Weights & Biases のプロジェクト名
- **`-wandb-entity "weblab-geniac1"`:** Weights & Biases のエンティティ名
## おわりに
Megatron-LMの概要とパラメータについて説明することが出来ました。
この概要等が今後の事前学習のナレッジ活用となることを期待しております。
最後に、このナレッジにご協力いただいた関係者の皆様に、深く感謝申し上げます。皆様のご協力のおかげで、このようなナレッジを作成することが出来ました。
---
13