**要約:** 私たちは、AI エージェントが実行できるタスクの「長さ」で AI のパフォーマンスを測定することを提案します。この指標は、過去 6 年間で 7 ヶ月ごとに 2 倍ずつ、指数関数的に増加していることを示しています。この傾向を推計すると、10 年以内に、現在人間が数日または数週間かけて実行しているソフトウェアタスクの大部分を、AI エージェントが独自に実行できるようになることが予測されます。

汎用最先端モデルエージェントが、人間のプロフェッショナルが完了するのに要する時間(タスクの長さ)を基準に、50%の信頼性で自律的に完了できるタスクの量は、過去6年間で7ヶ月ごとに約2倍に増加しています。陰影部分は、タスクのファミリー、タスク、タスクの試行回数を階層的ブートストラップで計算した95%信頼区間を表しています。
[フルペーパー](https://arxiv.org/abs/2503.14499) | [Githubレポ](https://github.com/METR/eval-analysis-public)
我々は、将来のAIシステムの能力を予測することは、強力なAIの影響を理解し、それに備えるために重要であると考えている。しかし、能力の傾向を予測することは難しく、今日のモデルの能力を理解することさえ混乱しかねない。
現在のフロンティアAIは、テキスト予測や知識タスクにおいて人間よりもはるかに優れている。ほとんどの試験形式の問題において、わずかなコストで専門家を凌駕する。タスクに特化した適応を行えば、多くのアプリケーションで有用なツールとしての役割を果たすこともできる。とはいえ、現時点では最高のAIエージェントも、単独で実質的なプロジェクトを遂行したり、人間の労働力を直接代替したりすることはできない。遠隔操作による経営者支援のような、比較的スキルの低いコンピューターベースの仕事でさえ、確実にこなすことができないのだ。ある意味で能力が非常に急速に向上していることは明らかだが、それが実社会への影響とどのように対応しているのかは不明である。
人間の能力に対するAIシステムのテストスコア】(https://metr.org/assets/images/measuring-ai-ability-to-complete-long-tasks/test-scores-ai-capabilities-relative-human-performance.png)
AIの性能は、さまざまな領域にわたる多くのベンチマークで急速に向上している。しかし、この性能の向上をAIの現実世界での有用性の予測に変換することは困難である。
我々は、モデルが完了できるタスクの長さを測定することが、現在のAIの能力を理解するのに役立つレンズであることを発見した[^1]: AIエージェントはしばしば、単一のステップを解決するのに必要なスキルや知識が不足している以上に、より長い一連の動作をつなぎ合わせることに苦労しているようだ。
我々は、多様なマルチステップのソフトウェアタスクと推論タスクについて、適切な専門知識を持つ人間がタスクを完了するのに必要な時間を記録した。我々は、人間の専門家による所要時間が、与えられたタスクにおけるモデルの成功を強く予測することを発見した:現在のモデルは、人間が4分未満で行うタスクではほぼ100%の成功率を示すが、約4時間以上かかるタスクでは成功率は10%未満である。これにより、「モデルがx%の確率で成功裏に完了できるタスクの(人間にとっての)長さ」によって、与えられたモデルの能力を特徴付けることができる。
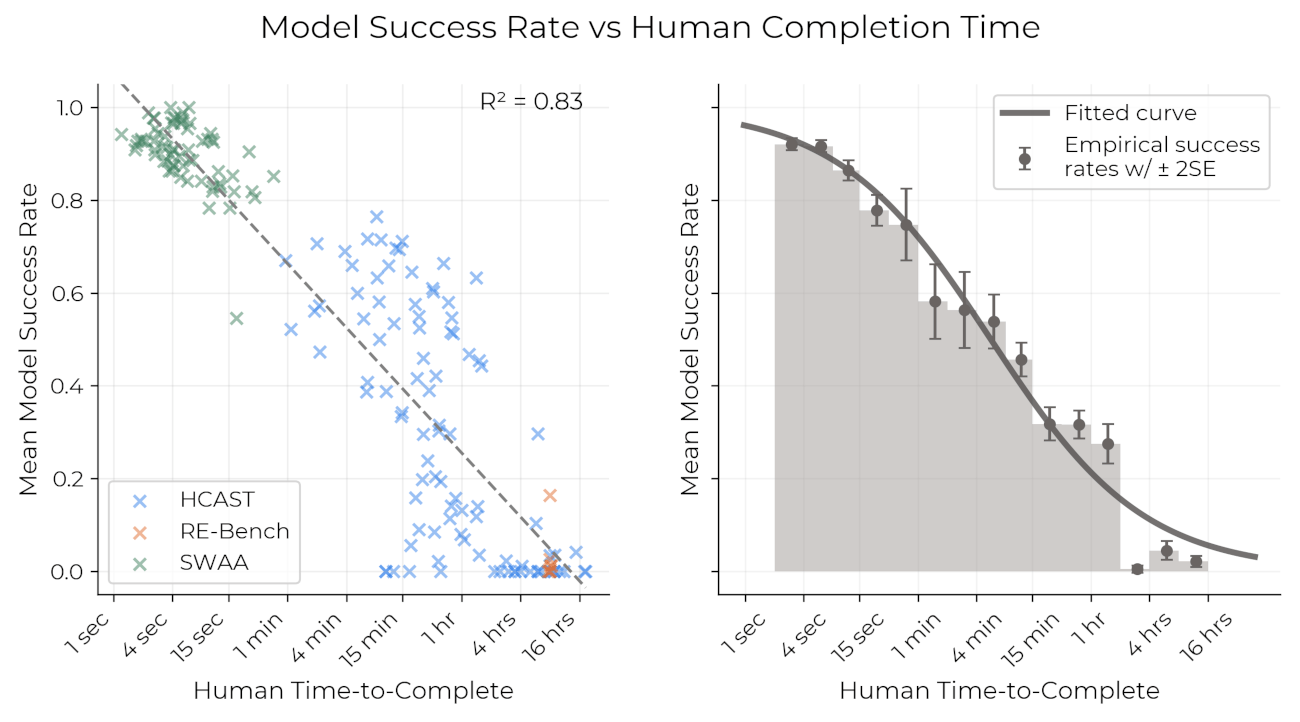
各モデルについて、我々は人間のタスクの長さを用いてモデルの成功確率を予測するロジスティック曲線を当てはめることができる。成功確率を固定した後、我々は、予測された成功曲線がその確率と交差するタスクの長さを見ることによって、各モデルの予測された成功曲線を時間に変換することができます。例えば、以下はいくつかのモデルの予測成功曲線と、我々が50%の成功率を予測したタスクの長さです:
モデルはますます長いタスクで成功しているチャート](https://metr.org/assets/images/measuring-ai-ability-to-complete-long-tasks/models-are-succeeding-at-increasingly-long-tasks.png)
時間地平線を計算するプロセスの描写。例えば、クロード3.7ソネット(一番右のモデル、一番濃い緑で表示)の時間地平線の長さは約1時間で、これはフィットしたロジスティック曲線が50%の成功確率の閾値と交差する場所だからです。
我々は、これらの結果が、多くのベンチマークにおける超人的なパフォーマンスと、モデルが人々の日常業務の一部を自動化するのに強固に役立つとは思われないという一般的な経験的観測との間の明らかな矛盾を解決するのに役立つと考えています:現在の最高のモデル(クロード3.7ソネットなど)は、熟練した人間でさえ数時間かかる*いくつかの*タスクが可能ですが、数分までのタスクしか確実に完了できません。
とはいえ、過去のデータを見ると、我々は、最先端のモデルが(50%の確率で)完了できるタスクの長さが、過去6年間で劇的に長くなっていることがわかる。
https://metr.org/assets/images/measuring-ai-ability-to-complete-long-tasks/length-of-tasks-linear.png
我々がこれを対数スケールでプロットすると、モデルが完了できるタスクの長さは指数関数的な傾向によってよく予測され、倍増する時間は約7ヶ月であることがわかります。
https://metr.org/assets/images/measuring-ai-ability-to-complete-long-tasks/length-of-tasks-log.png
エージェントが完了できるタスクの長さの見積もりは、使用するタスクやパフォーマンスを測定する人間のような方法論的選択に依存します。しかし、全体的な傾向としては、1年に2倍から4倍程度であり、ほぼ正しいと確信している。過去6年間の測定傾向があと2~4年続けば、ジェネラリスト型自律エージェントは、1週間にわたる幅広いタスクをこなせるようになるだろう。
このトレンドの急勾配は、測定誤差やモデルと人間の比較誤差が大きくても、さまざまな能力がいつ到達するかについての我々の予測が比較的頑健であることを意味する。例えば、絶対測定値が10倍ずれても、到着時期は2年程度しか変わらない。
我々は結果の限界について議論し、様々なロバストネスチェックと感度分析の詳細を[論文全文](https://arxiv.org/abs/2503.14499)で述べている。簡潔に述べると、我々は同様の傾向が(よりノイズが多いとはいえ)以下のような場合にも成り立つことを示している:
1. 1.異なる分布(非常に短いソフトウェアタスク対多様なHCAST対RE-Bench、長さや「雑さ」の定性的評価でフィルタリングしたサブセット)を表す可能性のあるタスクの様々なサブセット。
2. 実際のタスク(SWE-Bench Verified)に基づく別のデータセットで、ベースラインではなく推定値に基づく、独自に収集された人間の時間データ。これは、3ヶ月未満というさらに早い倍増時間を示している[^2]。
モデルはますます長いタスクで成功しているチャート](https://metr.org/assets/images/measuring-ai-ability-to-complete-long-tasks/time-horizon-swe.png)
我々はSWEベンチ検証で結果を再現し、同様の指数関数的傾向を観察した。
我々はまた、我々の結果が、どのタスクやモデルを含めるか、また我々が調査した他の方法論的選択やノイズ源に対して、特に敏感ではないようであることを論文で示す:
1ヶ月AIチャートの外挿日付の不確実性](https://metr.org/assets/images/measuring-ai-ability-to-complete-long-tasks/uncertainty-in-extrapolated-date.png)
フロンティアAIシステムの地平線が1ヶ月になる外挿日付の感度分析。各行では、我々はデータに10,000のランダムな摂動を適用し、摂動データによって暗示される1ヶ月のAI開始日の分布を求める。ボックスの端点は25パーセンタイルと75パーセンタイル、ひげは10パーセンタイルと90パーセンタイルを表し、外れ値は表示しない。このプロットでは、不確実性の大部分を占めるトレンドの将来の変化や外部妥当性の懸念は考慮されていないことに注意されたい。
しかし、モデルに大きな誤差がある可能性も残っている。例えば、AIの最近のトレンドは2024年以前のトレンドよりも将来のパフォーマンスを予測しやすいと考えられる理由がある。上に示したように、我々が2024年と2025年のデータだけに同様の傾向を当てはめた場合、AIが50%の信頼性で1ヶ月のタスクを完了できる時期の推定が約2.5年短縮される。
### 結論
我々は、この研究がAIのベンチマーク、予測、リスク管理にとって重要な意味を持つと信じている。
第一に、我々の研究は、ベンチマークを予測により有用なものにするためのアプローチを示している。それは、システムが完了できるタスクの*長さ*(タスクが人間に要する時間によって測定される)でAIのパフォーマンスを測定することである。これによって、幅広い能力レベルと多様な領域にわたってモデルがどのように改善されたかを測定することができる[^3]。同時に、実世界の結果との直接的な関係によって、相対的なパフォーマンスだけでなく、絶対的なパフォーマンスを有意義に解釈することができる。
第二に、我々は、実社会への影響に重要な指標において、長年にわたるAIの進歩がかなり強固な指数関数的傾向を示していることを発見した。過去6年間のトレンドがこの10年の終わりまで続けば、フロンティアAIシステムは、1カ月に及ぶプロジェクトを自律的に遂行できるようになるだろう。これは、潜在的な利益と潜在的なリスクの両面で、莫大な賭けとなる[^4]。
### 貢献したいですか?
私たちは、この研究がAIエージェントの評価に関する先行研究の上に構築されているように、他の人々がこの研究を基にし、基礎となるアイデアを推し進めることを非常に楽しみにしています。そのため、我々は[インフラ](https://github.com/METR/vivaria)、[データと分析コード](https://github.com/METR/eval-analysis-public)をオープンソースにしている。上述したように、この方向性は将来の評価設計に大きく関連する可能性があるため、再現や拡張はAIの現実世界への影響を予測する上で非常に有益であろう。
さらに、[METRは求人中である](https://hiring.metr.org/)!このプロジェクトにはMETRのほとんどのスタッフが何らかの形で関わっており、我々も現在、同様のエキサイティングなプロジェクトにいくつか取り組んでいる。もしあなたやあなたの知り合いがこのような仕事に適しているのであれば、掲載されている役割をご覧ください。
``bibtex
misc{measuring-ai-ability-to-complete-long-tasks、
タイトル = {長いタスクを完了するAI能力の測定}、
author = {METR}、
howpublished = {url{https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/}}、
年 = {2025}、
month = {03}、
}
```
[^1]: これはRichard Ngoが[t-AGI](https://www.alignmentforum.org/posts/BoA3agdkAzL6HQtQP/clarifying-and-predicting-agi)と呼んでいるものに似ており、Ajeya Cotraの[Bio Anchors report](https://www.lesswrong.com/posts/FbP7EteJBCx8FpLFn/the-bio-anchors-forecast)などの先行研究でも検討されている。
[^2]: これは、少なくとも部分的には、時間推定の運用方法に起因していると思われる。著者らは、コードベースに慣れるために必要な時間をタスク時間の一部として含めていない。これは、短いタスク(慣れるまでに総時間の大部分を占める)の時間推定に大きな影響を与えるが、長いタスクにはそれほど影響を与えない。したがって、同じタスクセットに対する人間の時間推定は、彼らの方法論ではより急速に増加する。
[^3]: ほとんどのベンチマークは、比較的狭い難易度範囲をカバーしているため、この基準を満たしません。この基準を満たさない他のベンチマークの例には、質問の難易度が多峰分布している場合や、一部の質問が解けない場合における「正解率(%)」のようなスコアが含まれます。
[^4]: AIシステムがはるかに長いタスクを完了できることを示す具体的な例については、[Clarifying and predicting AGI](https://www.alignmentforum.org/posts/BoA3agdkAzL6HQtQP/clarifying-and-predicting-agi)を参照してください。課題とメリットの具体的な例については、[Preparing for the Intelligence Explosion](https://www.forethought.org/research/preparing-for-the-intelligence-explosion) および [Machines of Loving Grace](https://darioamodei.com/machines-of-loving-grace) を参照してください。