本記事は、[2023年夏季インターンシッププログラム](https://www.preferred.jp/ja/news/internship2023/)で勤務された石森大路さんによる寄稿です。
---
こんにちは。[PFN2023 夏季国内インターンシップ](https://www.preferred.jp/ja/news/internship2023/)に参加していた大阪大学3年の[石森大路](https://twitter.com/ciffelia)です。私はPFNの機械学習基盤を開発、運用するCluster Servicesチームにおいて、「キャッシュを利⽤した機械学習・深層学習ワークロードの加速」というテーマで課題に取り組みました。
## 分散キャッシュシステム
Cluster Servicesチームでは、機械学習データセットをはじめとする大容量データの読み込みを高速化する分散キャッシュシステムを開発しています。キャッシュシステムの細部については次の記事や発表において詳しく説明されていますが、この記事でも改めて簡単に説明します。
[深層学習のための分散キャッシュシステム – Preferred Networks Research Development](https://tech.preferred.jp/ja/blog/distributed-cache-for-deep-learning/)
[分散キャッシュシステム on Kubernetes / Kubernetes Meetup Tokyo 60 – Speaker Deck](https://speakerdeck.com/pfn/k8s-tokyo-60-distributed-cache-system)
このキャッシュシステムは、Kubernetesベースの機械学習基盤におけるデータセット読み込みの高速化を目的としてつくられました。図1に示すようにREST APIを通して社内の機械学習基盤で提供されており、既に社内で複数のプロジェクトにおいて利用されています。
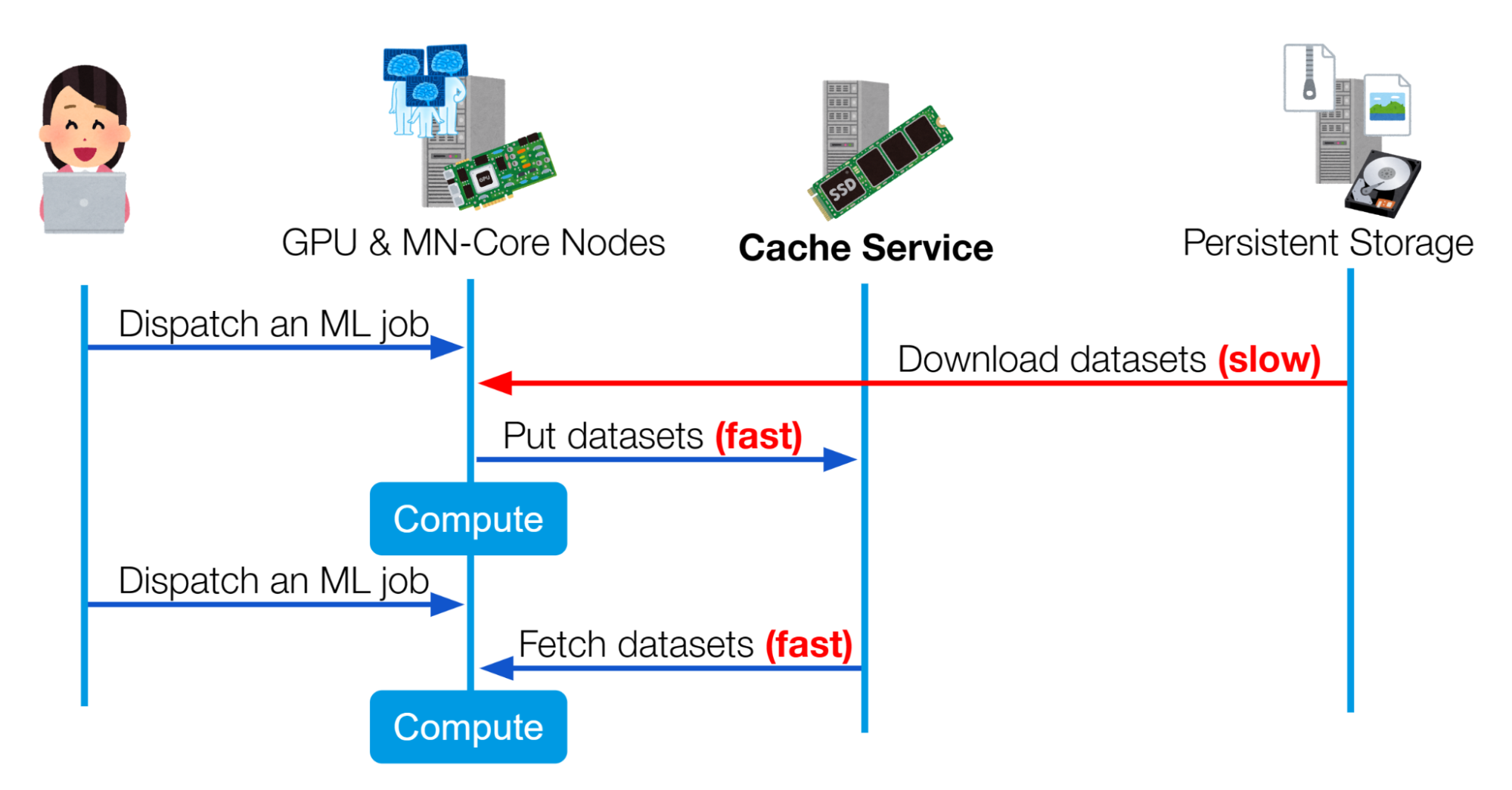
図1 社内の機械学習基盤においてキャッシュサービスを使用する流れ
キャッシュシステムは以下に示すようにオブジェクトストレージと類似するインターフェースを備えており、ユーザーはファイルをオブジェクトとしてバケットに保存できます。バケットはファイルを格納するための領域で、デフォルトでユーザーごとに割り当てられますが、複数のユーザーやプロジェクトで共有されたバケットを作成することもできます。
| 1 2 3 4 5 6 7 | `$ curl -H ``"Authorization: Bearer $(cat /token)"` `-X PUT` `http:``//cache``.cache-service.svc``/v1/objects/prj-foobar/apple` `--data-binary @apple.jpg` `$ curl -H ``"Authorization: Bearer $(cat /token)"` `-X GET` `http:``//cache``.cache-service.svc``/v1/objects/prj-foobar/apple` |
| --- | --- |
このシステムの特徴として、スケーラビリティの高い分散システムとして設計されているという点があります。図2に示すように負荷が各Podに均等に分散されるようになっており、Envoy PodやBackend Podを増やすことで水平方向にスケールすることが可能となっています。
このストレージシステムはあくまでもキャッシュシステムであるため、キャッシュデータが予告なく消えることは許容しています。実際、各ノードの容量制限に達した際にはLRU (Least Recently Used)に基づいて自動的にファイルが削除されるようになっています。
## 取り組んだ課題
このキャッシュシステムが直面していた課題の1つに、ユーザーごと・プロジェクトごとの利用量制限が存在しないというものがありました。キャッシュシステムに保存できる容量には限界があるため、1人のユーザーが連続して大容量の書き込みをしてしまうことで、容量の上限に達し、最近アクセスしていなかった他のユーザーのキャッシュデータが短時間で追い出されてしまう可能性があります。これを防ぐために、各ユーザーはキャッシュシステムに大量のデータを書き込まないよう注意する必要がありました。
複数のユーザーがキャッシュシステムに連続して大容量の書き込みを行う状況を想定した、小規模な実験を行った結果を図3に示します。
図3は、4人のユーザーが連続してデータを書き込んでキャッシュサービスのストレージを奪い合う様子を示しています。最終的には、一番最後に書き込んだprj-03のデータが他のユーザーのデータを追い出し、キャッシュサービス全体を占有していることが分かります。
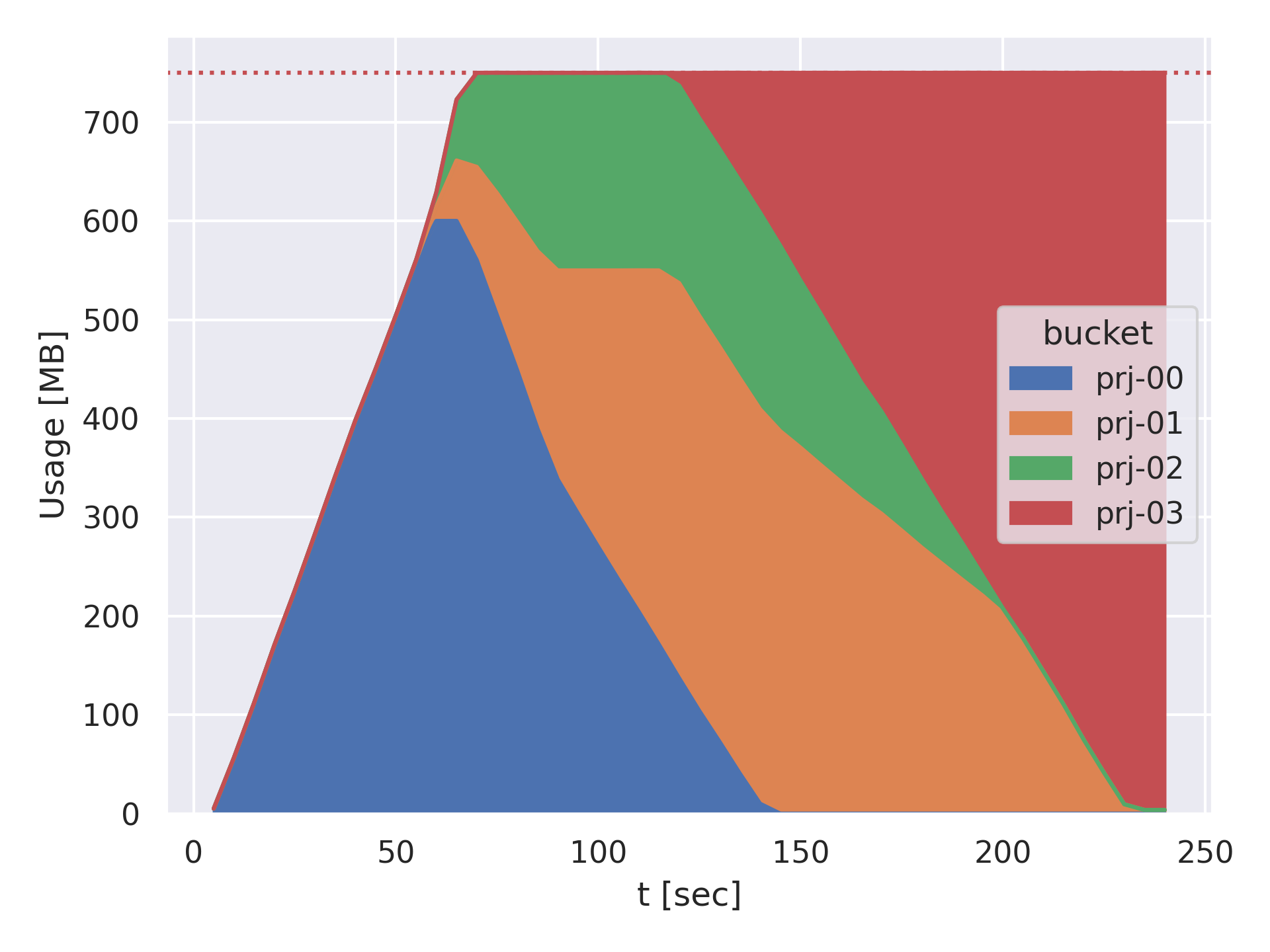
図3 4人のユーザーがデータを並行に連続して書き込む実験におけるユーザーごとのキャッシュサービス使用量の変化
## 設計
この「連続したデータの書き込みによりキャッシュシステム全体を占有できてしまう」問題を解決するために、私たちはバケットに対する容量制限を実装することにしました。具体的な仕様は次のようになっています。
- 各バケットに対して事前に容量上限 (Quota)を設定できるようにする。
- プロジェクト・ユーザーによって使用したいバケットの容量が異なるので、バケットごとに容量上限を設定できる必要があります。
- とくに容量上限が設定されていないバケットに対しては、デフォルトの容量上限を適用します。
- あるバケットの容量が上限に達したとき、そのバケットの中で最も最終アクセス日時が古いデータを削除する。
- また、従来どおりキャッシュシステム内のあるノードの容量が上限に達したときには、そのノードの中で最も最終アクセス日時が古いデータを削除する。
- これは、容量上限はオーバーコミットして払い出すことができる、ということを意味しています。
この仕組みにより、各ユーザーは他ユーザーのことを気にせず好きなだけデータを書き込めるようになると考えました。
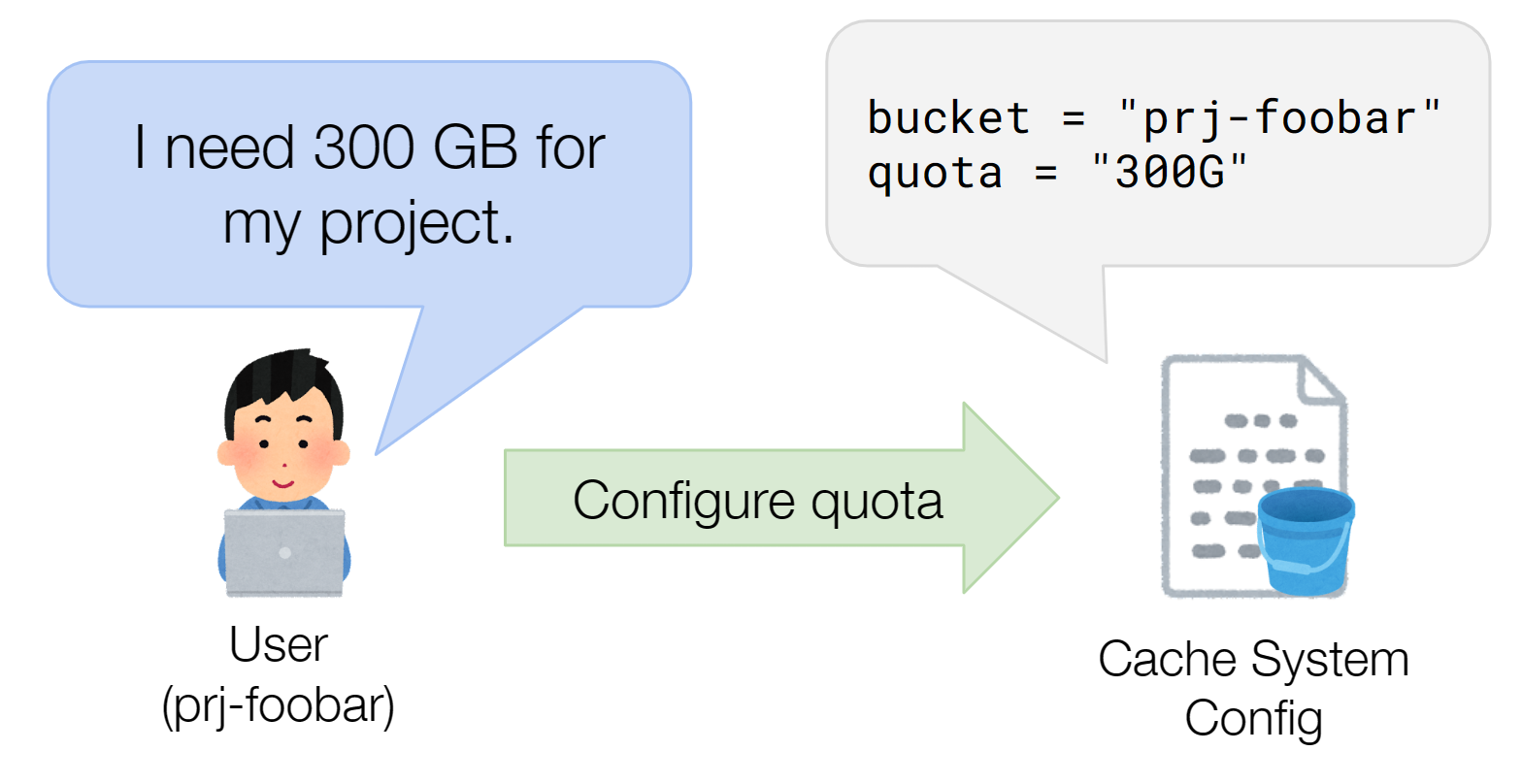
図4 ユーザーが容量上限を申請するイメージ
このような機能の実装は一見シンプルに見えますが、実は難しいポイントがあります。それはキャッシュデータが複数のノードに分散して保存されている点です。
私たちのキャッシュシステムは、図2に示したようにキャッシュデータを保存するノード間で一切の通信を行わないシェアード・ナッシング・アーキテクチャとなっています。このような設計により、シンプルな実装で低いレイテンシと高い可用性が実現されています。
しかし、各バケットの利用量を集計するためには、何らかの方法で現在の利用量を共有するための通信を行う必要があります。この集計をリアルタイムで行うには、キャッシュデータを格納するたびに統計情報を送受信する必要があり、キャッシュサービスに求められるレイテンシの面からは現実的ではありません。また、ある一定の間引いた間隔で利用量を集計する場合は、ユーザーが短時間で大量のデータを格納した場合に容量上限を超過するため、なんらかの制御アルゴリズムを考える必要がでてきて複雑になってしまいます。
本インターンシップでは、シンプルな解決策として、キャッシュシステム全体でのバケットごとの容量上限を予めノード数で割っておいて、その値を各ノードにおける各バケットの容量上限とすることにしました。例えばノード数が3台のキャッシュシステムにおいて、あるバケットのキャッシュシステム全体での容量上限が300GBのとき、各ノードはそのバケットのデータを100GBまで受け入れるようにします。
このような設計により、レイテンシと可用性を維持したまま容量制限を実現できます。
## 実装
上記の方針で容量制限を実装しました。図3で行ったのと同じように、複数のユーザーがキャッシュシステムに連続して大容量の書き込みを行う状況を想定し、小規模な実験を行った結果を図5に示します。
4人のユーザーが連続してデータを書き込んでいますが、どのユーザーも自身のバケットに割り当てられた容量上限以上は使用できず、最終アクセスが古いデータから順に削除されています。これにより特定のユーザーがキャッシュシステム全体を占有することはなくなりました。また、システム全体の容量に達したあとは、それぞれのバケットからアクセス順序に従ってデータが削除されています。
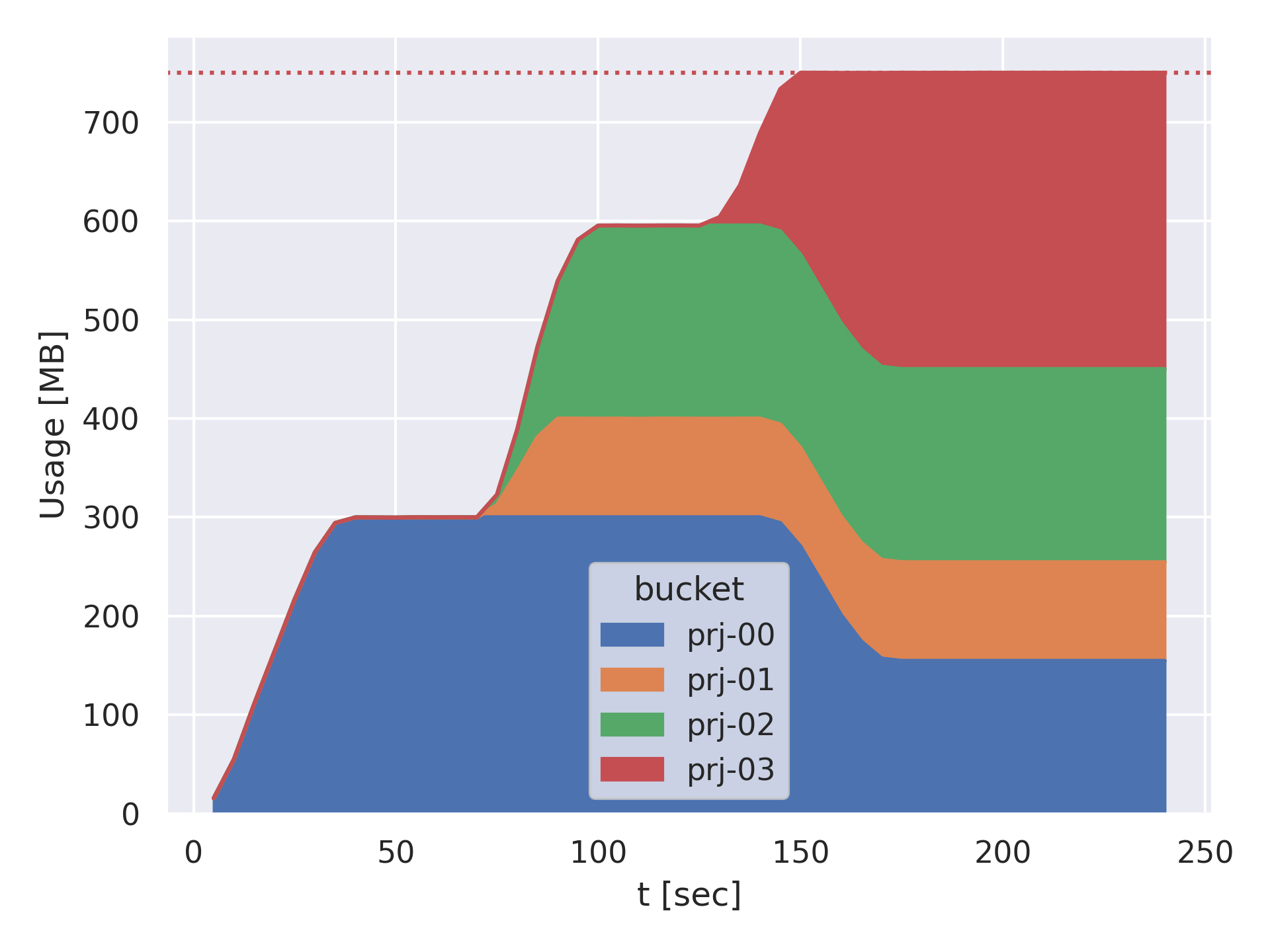
図5 容量制限実装後の、4人のユーザーがデータを書き込むシミュレーションにおけるユーザーごとの使用量の変化
## 容量上限の断片化問題
前述した設計には、ユーザーが事前に設定した容量上限を超えていないにもかかわらず、データを格納できないという問題があります。例えば図6のようにあるユーザーの容量上限が300GB、ノード数が3台のとき、各ノードにおける容量上限は100GBとなります。このとき、ユーザーは150GBのファイルを書き込むことができません。
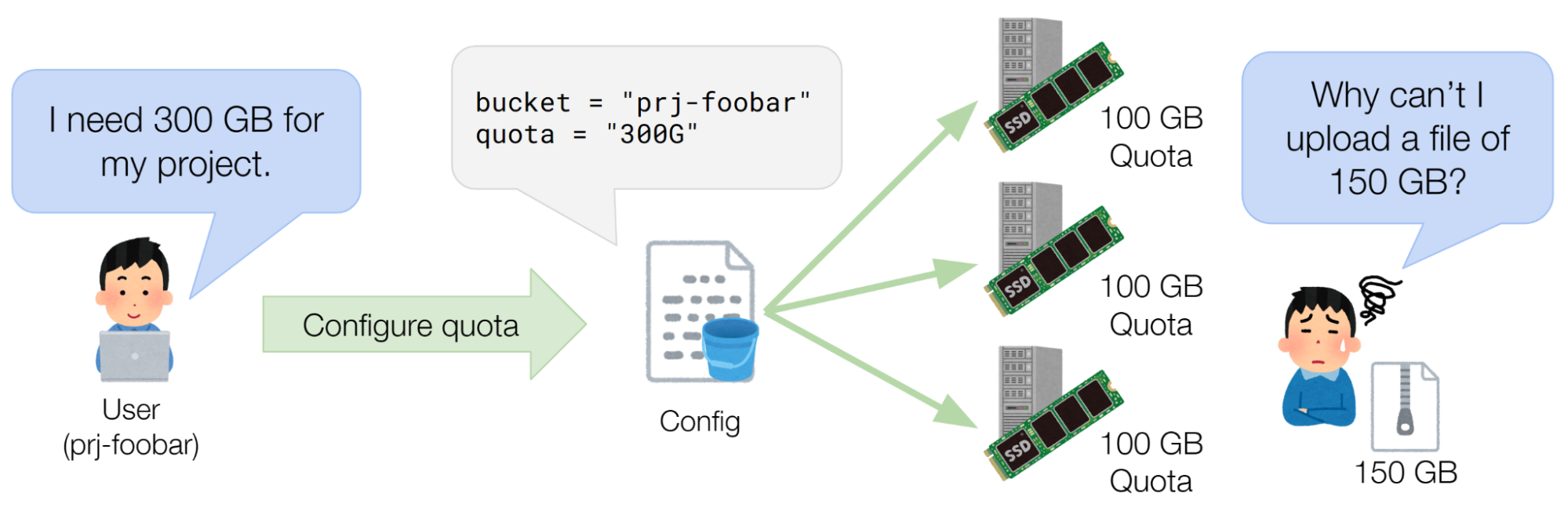
図6 ユーザーが事前に設定した容量上限を超えていないにもかかわらず、データを格納できない状況
また、各ノードにおける容量上限、すなわちユーザーが申請した容量上限をノード数で割った値は、ノード数の増減により変化します。先ほどの例では100GBまでのファイルを格納できていましたが、図7に示すようにノード数を4台に増やすと75GBまでのファイルしか格納できなくなります。
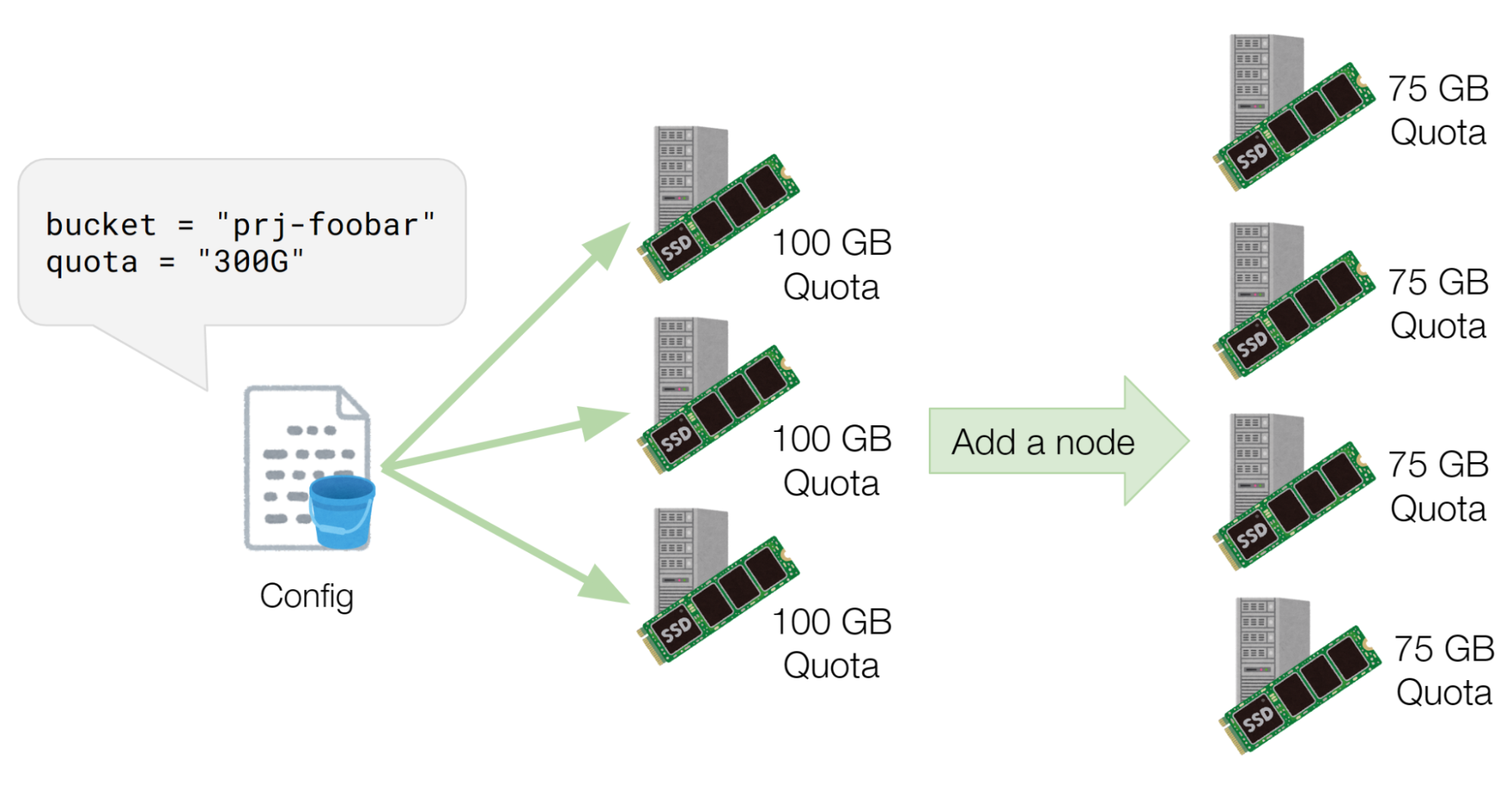
図7 ノードが1台追加されたときのQuotaの変化の様子
私たちはこの問題をQuota Fragmentationと名付けて、さらに調査することにしました。
もしユーザーがキャッシュシステムに格納しているファイルが十分小さい場合、この問題の影響は現時点では無視できます。なぜならば、この問題は1つのキーに対して大きなファイルを保存しようとした時に、それがノードあたりの容量上限を超えた際に発生する問題だからです。そこで、Quota Fragmentationの解決策を検討する前に、そのような問題が実際に発生するかどうかを見極めるため、各バケットの最大ファイルサイズをメトリクスとして確認できるようにしました。
本キャッシュシステムでは、ノードに格納されているファイルの一覧は、レイテンシの観点からオンメモリで管理されています。システム内部では、ノードごとにLeast Recently Usedのキャッシュ戦略を実装するため、最終アクセス日時でソートした連結リストを管理しています。このデータ構造上では、最大サイズのデータを検索するためには全件を走査する必要があり、このようなクエリを効率的に実行できません。

図8 連結リストでの容量管理
本システムは、現在ノードあたり数百万のファイルを管理しており、*O(n)*のアルゴリズムは遅すぎます。そのため、赤黒木を用いた構造を連結リストの他に導入し、サイズが最大となるファイルの探索や任意のエントリの挿入と削除を*O(log n)*の計算量でできるようにしました。この変更はパフォーマンスに影響がないことを確認した上で、インターン期間中に社内の本番環境のクラスタへデプロイされました。
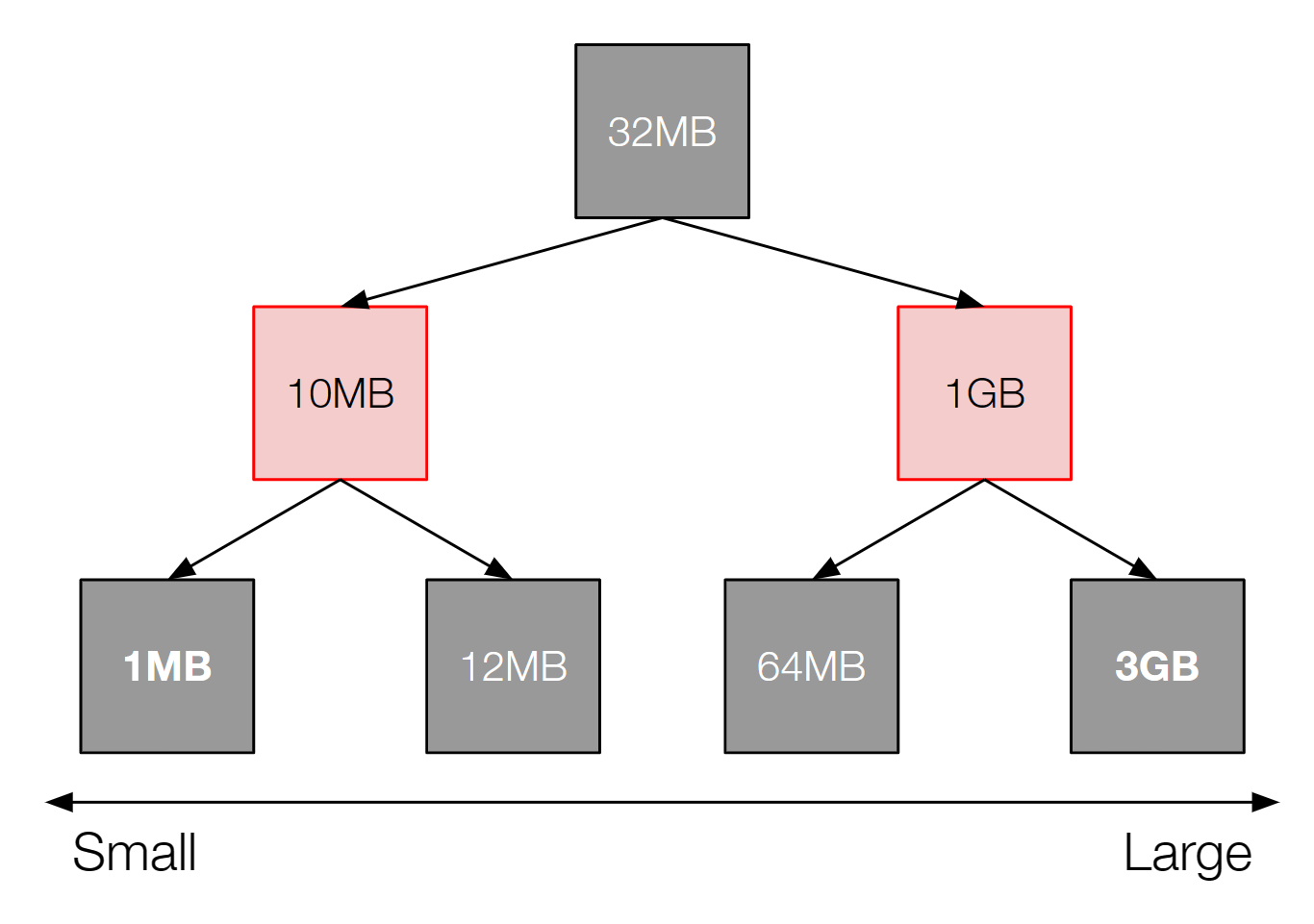
図9 赤黒木を用いた容量の管理
このようにして各バケットにおける最大ファイルサイズと平均ファイルサイズを確認したところ、現時点ではどちらも十分小さいことがわかりました。一部のバケットでは大きなファイルが存在していましたが、影響は限定的で個別に対処できるレベルだと判断しました。また、この問題を解決する策の候補がいくつか思い浮かんでいたため、まずは前述の方針で実装を進めました。
ただし、Quota Fragmentationは現状では問題ないものの、ノード数の増加により将来的に大きな問題になる可能性があるため、本インターン期間内でアイデアを検討しました。結論としては図2におけるEnvoyプロキシの部分を拡張または独自実装して、大きなサイズのオブジェクトを挿入時に分割して複数のBackend Podに保存するという方法が最も実現可能性が高いと判断しました。対案として、ノード間で使用量や空き容量などの情報を交換することも考えました。しかし、この案では先述したようにパフォーマンス、可用性のいずれかが犠牲になるという結論になりました。
## インターンシップの感想
今回のインターンでは、分散キャッシュシステムにおける公平な利用を実現する機能の設計と開発に取り組みました。この課題は一見シンプルなようで様々な制約と向き合う必要があり、取り組みがいのある課題となりました。
私がインターンに応募した際は、事前に公開されていたテーマに対する好奇心やPFNで働く方々に対する興味からPFNのインターンシップを選びました。インターン期間中は、取り組んだ課題はもちろん、社員や他のインターンの方々との交流を通して期待を裏切らないような刺激的な体験をさせていただきました。特に、設計や実装において様々な問題に直面する中で、何度も相談に乗っていただいたメンターの小松さんと上野さん、そしてクラスタ関連のチームの方々には大変お世話になりました。
6週間という短い期間でしたが、今後の糧となる経験をさせていただきありがとうございました。
---
## メンターより
石森さんのメンターを務めました、PFNでオンプレミスクラスタ上のサービスを担当している小松です。今回は、既に社内のクラスタで動作している分散キャッシュシステムの改良について取り組んでいただきました。本課題には分散システム特有の難しさと、キャッシュシステムが要求する厳格なレイテンシという問題が存在していました。しかし、石森さんにはアーキテクチャ、メトリクスのデザインから実装、動作の確認、さらに既存動作中のキャッシュシステムへの組み込みまでを含む運用面まで達成してもらいました。
PFNでは、機械学習/深層学習そのものの研究だけでなく、分散キャッシュシステムなどそれらを支えるクラスタの研究開発、構築、運用も行っています。もしご興味がある方、我こそはという方がいらっしゃいましたら、ご連絡お待ちしています。
- [カジュアル面談応募フォーム](https://docs.google.com/forms/d/e/1FAIpQLSf3gUARsdrHSlyiHytuOBYpSvXqVA0kulZmWEZjhyfqDoknHw/viewform)
- 募集
- [機械学習プラットフォームエンジニア](https://apply.workable.com/preferred-networks/j/150BE9CDDC/)
- [ストレージエンジニア](https://apply.workable.com/preferred-networks/j/ECD7ADAEF9/)
- [大規模計算基盤エンジニア](https://apply.workable.com/preferred-networks/j/6CDF8CA1A8/)
また、残念ながら今年のサマーインターンは終わってしまいましたが、来年のサマーインターンの応募もお待ちしています。